Since the advent of the internet many GLAM’s (Galleries, Libraries, Archives and Museums) seem to be struggling with the same issue: what’s the best way to publish data online in a format that can be easily used, reused and linked to?
Because the W3C is a non-profit organization it is of little surprise that many GLAM’s see these technologies as the logical solution to their problems.
Although the intentions of the W3C are good i don’t think the solutions as envisioned by the W3C are the best match for GLAM’s. Frankly, the proposed technologies are mostly of little to no use for most GLAM’s at all. Let me explain why.
A solution looking for a problem
Here’s the main problem: the semantic webtechnologies are solutions looking for a problem. Instead of a solution for an actual problem (how can GLAM’s make their data easily available on the web?) the semantic web repurposes mostly obsolete technologies under the new moniker of ‘linked open data’ as the silver bullet to every technological problem.
Why are these technologies useless? Here’s the simple reason: how many succesful ‘semantic’ projects can you name that have broad adoption, not only with GLAM’s, but also at other web projects?
Well, i actually know of a few. But they’re not the ones advocated by the W3C.
Here’s one: Open Graph, also known as ‘the Facebook tags’, is a way to annotate a webpage with some simple metadata, like a thumbnail image and a type (such as ‘video.movie’). It’s widely used, by almost 50% of all shared webpages.
Do webmasters add these tags because they want to add ‘semantic meaning’ and ‘linked data’ to their websites? Of course not, they simply want to have a thumbnail and a proper description whenever somebody shares their pages on Facebook.
So, why does Open Graph works where the semantic technologies fail? It’s very simple: it solves a problem. Given that it’s very easy to implement and the #2 website in the world actively supports it is probably a reason of its success as well.
The hell of XML
Here’s another problem with the semantic technologies. All of the semantic technologies are based on XML, and developers hate XML.
So, what do developers want? Developers simply want what we all want: something simple and easy that works most of the time. That’s why virtually all new API’s have settled on JSON as the best data format instead of XML.
Yes, there are semantic formats in JSON, such as JSON-LD. Unfortunately, the origin of the format, which is XML, is clearly visible in the ‘translated syntax’, which is still unwieldly and unnecessary verbose.
The semantic technologies are tricky to implement, so highly skilled developers are necessary. Unfortunately most GLAM’s don’t employ those in abundance. GLAM’s that actually build their sites ‘in-house’ are a minority, they usually outsource to external web developers. Do you think the nerds there have ever heard of OWL or SPARQL? Nope. But they do know how to parse JSON and do HTTP calls for sure.
Standards and the W3C
But, the semantic web standards are written by the W3C, the place of Sir Tim Berners-Lee, the inventor of the world wide web, surely it must be good?
Unfortunately, most of the standards the W3C develops have little practical use on the ‘real web’. You know HTML5, the standard that gave us useful things like native video and app-like features on the web? None of that came from the W3C. If the W3C would have it their way we would be writing strictly valid, non-backwards compatible XHTML (HTML written as XML). And it probably meant we’ll still be living in the dark ages of Flash and Silverlight to get real stuff done.
On the web, new technologies are usually taken up within months of release. Everything that hasn’t be widely used for a year or two is considered ‘legacy’ (think Flash or Silverlight again).
Look at the semantic technologies again in that context: the first version of the RDF spec is from 1999, OWL is from 2002. How many interesting posts on OWL or RDF do you think are posted on heavily visited developer sites like Hacker News?
Misconceptions on webservices
Another thing that most people propogating semantic web technologies tend to forget is that making a webservice (such as an API) work properly is hard work. It doesn’t come for free with your technology.
This means that your service:
Should be fast and responsive, even with many people using it at the same time
Obviously all of my ranting serves little purpose if i don’t give you an alternative. Most of the principles of the linked data movement are actually good, but the implementation is where the wrong decisions are made.
The most frustrating aspect of the whole ‘everyone should use semantic web technologies’ is that organizations are spending money on useless technologies like triple stores where they could be spending it on stuff that’s actually useful.
Actually, the very first thing you should do is take a hard look at your website, not at the data behind it. Developers are one of your customers, but your very first priorirty should be your regular customers.
So think of the visitors to your museum, or the people in your library. Can they view your website properly on their smartphones? Does the site load fast enough (that means, under 3 seconds)? Is everything easily findable? Are the texts up-to-date? What about the design?
If your website still looks like it’s 1999, maybe it’s time to update that instead of thinking about the ideal world of SPARQL endpoints and structured RDF.
Actually, rebuild your website as the first customer of your API. They can be developed in a tandem, and your webdevelopers will give you invaluable feedback on the use of your API.
Putting it into practice
So, let’s get back to your API. Let’s take the vision of linked data according to Wikipedia:
(…) a method of publishing structured data so that it can be interlinked and become more useful (…) to share information in a way that can be read automatically by computers.
Here are a few things you can do to get to that vision:
Permalinks
Have permanent URL’s to your items. If you have a website with paintings don’t have an URL like
Don’t laugh, that’s an actual link. Here’s a better solution:
http://www.musee-orsay.fr/work/000747
Machine-readable data
Offer some kind of machine readable data. If you don’t have the money to develop a full-fledged API that’s fine, CSV dumps are better than nothing.
If you are building an API, at the most basic level, something like
http://www.musee-orsay.fr/work/000747.json
Is okay. If you can deliver a ‘real’ API, that’s cool too. Make it simple. Don’t force people to use an API key. You want to offer a search option? What about something like:
http://api.musee-orsay.fr/search/?q=rembrandt
JSON
JSON should be the only output format. Everybody is doing it. So can you. You really don’t need a XML schema. Nobody will use it. Not quite sure how to translate your existing XML schema to JSON? Take the JSON output from the Europeana API as an example.
Documentation
Instead of trying to shoehorn your data in some metadata format put all your effort in documenting your metadata fields. Your ‘format’ field includes width and height of a painting, but it could also include ‘jpeg’? Fine, tell us about that weird stuff.
Code
If the only way you can deliver documentation on your website is in the form of a PDF file you’re doing it wrong. For developers the main place where they find code and documentation is Github. If you’re writing an example library for your API this is also the place to host it. You can also use Github pages to host your documentation. For a nice example view the Rijksmuseum API docs and their Github profile.
To conclude
Thanks for reading this article. If you think it’s useful, please share it using your favourite medium. Remarks or questions? Add a comment. And for more rambling about stuff like this, follow me on Twitter.
Stubbs is a 16-year old cat from Talkeetna, Alaska. Apart from being a resident, he’s also the mayor of the 876 residents of the little town. A bit weird perhaps, but apparently in the USA cats are smart enough to govern a town.
I found out about the existence of Stubbs through Wikidata, more specifically using Magnus‘ WikiDataQuery. It’s a fun tool to query the almost 15 million items available there.
My query was pretty simple: give me all items that have a ‘position held’ of ‘mayor’ and are not an instance of ‘human’. Turns out there’s actually one other non-human mayor in Wikidata: Samwise Gamgee, from Tolkien’s Lord of the Rings.
I admit that querying Wikidata for non-human mayors might not be the most useful thing in the world, but it shows that the system works and can lead to interesting facts.
The last few weeks i’ve been dabbling around with Python. I’m busy doing some experiments with OpenCV, and because it has Python bindings it seemed like a good excuse to dive a little bit more into Python.
Here are some of my observations, from somebody with a background in mostly frontend jobs, usually Javascript/Node.js and/or PHP.
Good
Python is mostly readable after a few months of not looking at it. I know the language is designed to do this, but it’s still pretty amazing when you dig up a script from a few months back and you don’t feel like reading Finnegan’s Wake.
Things usually do what they should do. There’s little confusion over methods. Getting the contents of a file is simply f = open("file.json").read()
The module system is easy enough to not overload with boilerplate when writing simple scripts, but powerful enough for writing large applications. It’s even easier than how Node.js does it, no module.exports, simply define functions, import the module and Bob’s your uncle.
It’s a small thing, but it pleases me that writing def is shorter than function in PHP/Javascript.
Package support is a lot better, it’s like the Mac app rule: packages simply seem better, especially if you compare it to the awfulness that is NPM modules (esp. in regards to documentation). Most packages seem written with the fact in mind that other people than the original coder are going to use it.
Python seems to strike a nice balance again between readability and longevity in the method names. It’s simply file.read, sys.exit. It’s a lot better than the confusing short PHP method names (srtolower vs nl2br) and the boring long Java methods (FileProcessingDecorator, readMultipleLineStrategy or whatever).
Even though i’ve read otherwise, for most of my uses, Python is fast enough.
Googling for common questions virtually always leads to a relevant, well written StackOverflow post.
Debugging seems easy. Most errors are readable and you never get the awful ‘white page of death’ like in PHP.
The internal help method is awesome, especially when combined with the powerful REPL. I love the fact that import mymodule even works in the REPL and you can do little tests and experiments.
Could be better
The documentation is not very good, especially compared to PHP. Reading the Python docs feels more like reading a language spec than something that helps you solve problems. Especially, there’s a lack of simple and clear examples. If i want to know something i usually Google something and end up at StackOverflow. That shouldn’t be the case. Even the Node.js docs seem more readable.
Here’s an example. Let’s say i want to know how to do the Python equivalent of PHP’s foreach. The docs about the for statement say this:
The for statement is used to iterate over the elements of a sequence (such as a string, tuple or list) or other iterable object:
for_stmt ::= "for" target_list "in" expression_list ":" suite
["else" ":" suite]
Right, so what does that mean? What’s ::=? What’s an ‘expression list’?
The expression list is evaluated once; it should yield an iterable object. An iterator is created for the result of the expression_list. The suite is then executed once for each item provided by the iterator, in the order of ascending indices.
“Ascending indices”? “Suite”? This might be clear for a CI professor, but it’s not for the mere mortals that read the docs and want to get stuff done.
And after reading this section i still don’t know how to do foreach in Python :(
Nice that the search works on the offline download though.
‘Variable hiding’ is confusing. I realise you shouldn’t be using def or if as a variable name, but because of ‘variable shadowing’ stuff like type or id might also not your best choice for a variable name, even though it makes a lot of sense. The convention seems to be to put an underscore after the variable (type_ or id_) but that looks like a clunky hack.
Adding to that, having modules in a directory that have the same name as a module give really weird error messages. For example, try naming a module stat.py and then run python.
lambda syntax seems somewhat…funny. Why can’t we have multiple-line lambda’s (yes, i know that’s why). For now, defining a function in a function and returning that feels like a kludge. Especially when doing anything complex with map or filter this is irritating.
Why can’t we have dot access to members of a dict? Writing dict[“instruments”][“guitar”] instead of dict.instruments.guitar because boring pretty fast. Furthermore, the difference between dicts, tuples, objects and what works as an options object in a function is confusing.
pip seems to do its job, but i’m still a little confused by how it works. What if i need a different version of a module than the one installed globally? Composer and NPM seem to handle this better.
It’s not as easy as PHP to write a simple webpage, although Flask makes it as easy as writing an Express.js app.
I should probably write something about Python 3 here. But on the other side, i haven’t really had any trouble with it. I guess. I don’t even know which version of Python i’m running. That might be something positive as well, i can’t count the number of times i’ve been cursing because a server didn’t have PHP 5.3 installed and i couldn’t use anonymous closures.
Why can’t we have json.loads(“file.json”)? The indent parameter in json.dumps is awesome though.
So, that’s my list. What are the things you like and hate about Python?
If you like this post, why not give a vote on Hacker News?
Alle mensen die een studieschuld hebben zullen de afgelopen dagen dit mailtje hebben gehad:
Dit mailtje is een perfect voorbeeld van hoe het niet moet. Want:
DUO weet wie ik ben. Wanner kan er niet ‘Geachte heer Kranen’ bovenaan dat mailtje staan?
Fijn dat ik gelijk een mededeling krijg over wat er allemaal fout kan gaan (“Leeg bericht”)
En vooral: leuk dat er een nieuw bericht voor me klaar staat. Alsof je een SMS-je krijgt waar in staat dat er een mailtje voor je is, of zo. Waarom kunnen ze dat bericht dan niet gelijk sturen?
Laten we dan maar eens kijken wat voor bericht er voor mij klaar staat. Na eerst diep nadenken welke inlog en wachtwoord ik had voor mijn DigiD krijg je dit:
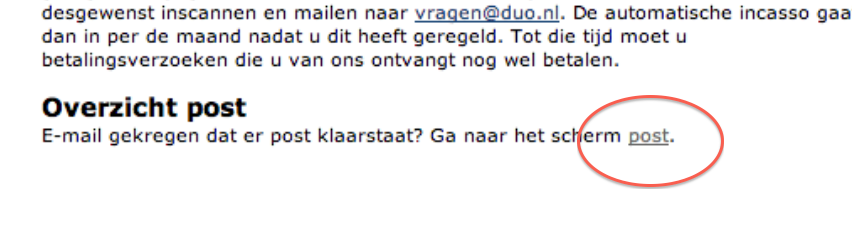
Zoekplaatje. Waar staat dat bericht? Juist:
Lekker vindbaar. Als je dan doorklikt krijg je eindelijk een PDF met dat bericht wat ze je ook gewoon hadden kunnen sturen.
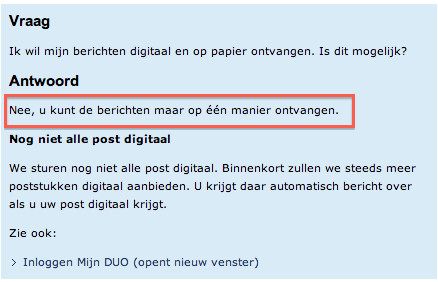
Ok. Weet je wat. Laat ze die brieven dan ook maar per ouderwetse post versturen. Dan hoef ik in ieder geval niet meer in te loggen om te lezen hoeveel geld ik dit jaar moet betalen aan Groningen. Maar wacht…
Lolwut? Dus je wilt me vertellen dat als er brieven worden verzonden het onmogelijk is om nog mailtjes te verzenden? Wie heeft dit idiote systeem gebouwd? Als ik zo de begroting mag geloven heeft DUO een jaaromzet van zo’n 231 miljoen euro per jaar. Daar kon toch wel een beter ICT-systeem van worden betaald?
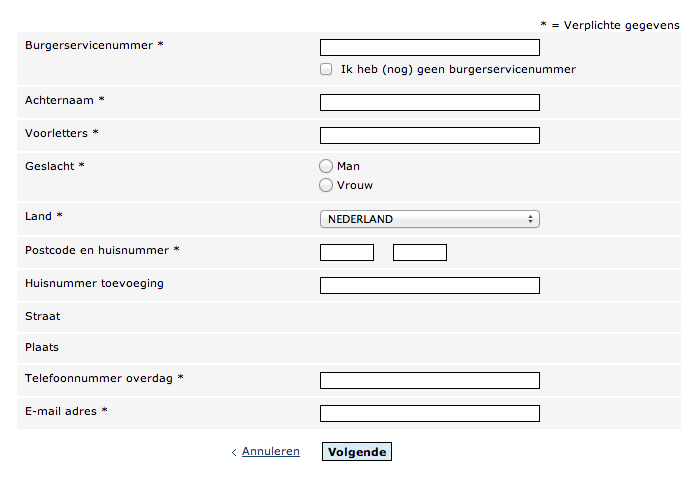
Ik heb het gehad! Ik ga een klacht indienen! Na tien keer klikken door het supportsystem van DUO krijg je dan dit:
Serieus gasten? Waarom moet ik mijn Burgerservicenummer en huisadres afstaan om te vertellen dat jullie website zuigt? Het is minder werk om een brief te sturen (of een blogpost te schrijven)!
Ik snap heus wel dat er vast goede redenen zijn waarom dit systeem zo slecht is. Maar, zoals ik al eens eerder schreef, de oplossing is niet om dan maar al die complexiteit bloot te leggen en het aan de klant over te laten om het op te lossen.
En waarom is dit nou belangrijk? Waarom word ik hier zo boos van? Die paar extra minuutjes die je extra moet spenderen omdat het systeem zo slecht is maken toch niet uit?
Echt wel. En als je het niet van mij wilt aannemen, dan maar van Steve Jobs. Want die vijf minuten van jou keer die miljoenen mensen die dit systeem gebruiken is mensenlevens vol van verspilde tijd die je ook had kunnen gebruiken, om, nou ja, bijvoorbeeld een goede website voor DUO te bouwen.
Naschrift: ik realiseer me dat DUO de PDF’s niet gelijk meestuurt omdat dat wellicht privacy gevoelige informatie bevat. Maar die redenatie zou op z’n minst moeten worden uitgelegd, of als keuze moeten worden aangeboden. Verder doet dat natuurlijk niks af aan de rest van de problemen die ik heb met de website. Dit is gewoon één onderdeel van de hele keten van onhandige onderdelen aan die website.
U bent het inmiddels van mij gewend: sinds 2004 zet ik op deze plek elk jaar een lijstje neer met de beste muziekalbums van het jaar.
2013 was een goed jaar. In tegenstelling tot 2011 en 2012 kon ik genoeg platen vinden om een lijstje mee te vullen en moesten er zelfs een paar afvallen om een top 20 te kunnen maken. Veel electronica, met een vleugje jaren-tachtig retro. Of zoiets. Eerlijk gezegd ben ik meer van het luisteren naar muziek dan er over te schrijven.
Bij deze dus. Als u Spotify heeft kunt u op het icoontje klikken om het album gelijk te luisteren. Ook heb ik een YouTube-mix toegevoegd met mijn favoriete twintig nummers van het jaar (scroll naar beneden voor die lijst). Tot 2014!
My Bloody Valentine – m b v
Kanye West – Yeezus
The Field – Cupid’s Head Zo goed als From Here We Go To Sublime wordt het uiteraard nooit meer, maar Cupid’s Head komt in de buurt.
Daft Punk – Random Access Memories
Oneohtrix Point Never – R Plus Seven
DJ Rashad – Double Cup
De Jeugd van Tegenwoordig – “Ja, Natúúrlijk!” Zo ongeveer een derde van de plaat is erg goed, een derde prima, en een derde compleet ruk. Maar genoeg goed dus voor een 7de plek.
Jon Hopkins – Immunity
Haim – Days Are Gone
James Blake – Overgrown
CHVRCHES – The Bones of What You Believe
Arcade Fire – Reflektor
Darkside – Psychic
Disclosure – Settle
The Knife – Shaking the Habitual
Kurt Vile – Wakin On A Pretty Daze
Phosphorescent – Muchacho
Lily & Madeleine – Lily & Madeleine Het is griezelig hoeveel Lily en Madeleine lijken op Johanna en Klara van First Aid Kit. Desondanks een prettig plaatje voor donkere winterdagen.
Savages – Silence Yourself
Vampire Weekend – Modern Vampires of the City De hekkensluiter. Zo’n beetje iedereen vond dit de plaat van 2013, maar eerlijk gezegd vond ik het zoals alle andere platen van Vampire Weekend: luistert prettig weg, maar na een paar keer heb je het wel gehad.
En nog even de tracks die je in de YouTube mix voorbij ziet komen, mijn favoriete losse tracks van 2013:
Naschrift: ontdek ik zowaar in mijn archieven dat ik deze lijstjes niet sinds 2004, maar zelfs al sinds 2003 jaarlijks maak. Een jubileum dus dit jaar. Hoera!
Ja, het is weer die tijd van het jaar. Wanneer kunt u het beste niet uw verjaardag vieren, of juist wél een goede detective kijken? Inderdaad, “onze jongens” spelen weer een WK. Hier alle tijden wanneer u het beste uw agenda kan blokkeren (om te kijken met uw vrienden) of wegkruipen in een hoekje (met die detective).
Vrijdag 13 juni 21:00 : Spanje – Nederland
Woensdag 18 juni 18:00 : Australië – Nederland
Maandag 23 juni 18:00 : Nederland – Chili
Mits Nederland tweede wordt in groep B:
Zaterdag 28 juni 18:00 : Achtste finale: Winnaar groep A – Nederland
Vrijdag 4 juli 22:00 : Kwartfinale: Nederland – Winnaar 1C / 2D
Dinsdag 8 juli 22:00 : Halve finale: Nederland – Winnaar kwartfinale
Mits Nederland eerste wordt in groep A:
Zondag 29 juni 18:00 : Achtste finale: Nederland – Tweede groep A
Zaterdag 5 juli 22:00 : Kwartfinale: Nederland – Winnaar 1D / 2C
Woensdag 9 juli 22:00 : Halve finale: Nederland – Winnaar kwartfinale
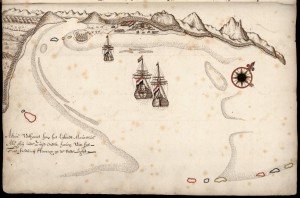
“De schoone slaapster in het bosch”, an interpretation of the story of Sleeping Beauty. From the collection of the Koninklijke Bibliotheek.
The past decade for libraries and archives have been hard. The ongoing digitisation of virtually everything that was once analog has led to confusion and soul searching for many of these GLAM’s (Galleries, Libraries, Archives and Musea): if their core mission is no longer about physical but virtual objects, what does it mean for their future?
At the same time, other initiatives have sprung up that compete with the traditional roles of these institutions. Wikipedia, being the 6th largest global website and the biggest reference work in the world, is perhaps the most important initiative in that respect.
It makes sense therefore to combine the two: why not have somebody from Wikipedia that can create a two-way relationship between the institution and the Wikipedia community?
I’ve been doing exactly that since october 7th as the first Dutch Wikipedian in Residence for the National Library (Koninklijke Bibliotheek, KB) and the National Archive (Nationaal Archief, NA). This blog post is a summary of what i’ve learned and encountered in those first two months.
Tone and focus
Together the National Library and National Archive have more than 220 kilometers of objects (that’s roughly the distance from Amsterdam to Brussels). That immediately raises the question: what small part of this huge collection should i focus on?
Fortunately i’m not the only one to decide. Together with collection specialists from both institutions, and many volunteers from Wikipedia i’m narrowing down the virtually endless list of options: among others, medieval illuminated manuscripts, historic maps and children’s picture books will all be part of some activity during my residency.
Evangelism and courses
Another important part of my residency here is the so-called ‘evangelism’ of all the concepts that float around Wikipedia: free licenses, no original research, ‘what is encyclopaedic?’, etcetera. In the two months that i’ve been working here more than 60 employees from the KB and NA have been following one of my five Wikipedia introductory courses where people learn both the ideas behind the encyclopedia and the practical side (how to edit).
Of course, i do not have the illusion that all of those 60 attendees will be full-time Wikipedia volunteers after a three-hour course, but it helps to create a sort of ‘baseline’ of common knowledge and goodwill. I don’t need to explain anymore why Wikipedia works the way it does after enough people have attended one of the courses.
Obviously, i do hope some people will become regular Wikipedia contributors. But for that, we’ll probably going to need some more ‘advanced’ courses (those will follow in the beginning of 2014). Still, we have some promising results after four workshops. Since i started here on October 7th, more than 170 edits have been made by people who attended one of the courses. 84 individual articles have been edited or created by KB/NA employees since i started here as a direct result of these courses.
Contact with Wikipedians
Wikipedians Ronn and Effeietsanders at the National Archive.
Apart from giving courses to employees one of my other tasks is getting in contact with any Wikipedians that want to use the resources and objects in the KB/NA collection.
Wikipedians Ronn and Effeietsanders (see photo) are working on improving all the articles related to the States-General (the Dutch legislature). Both the KB and NA have important documents related to the history of the States-General (going back to 1464) , and i was happy to help them with finding documents and directing their specific questions to the specialists about this subject.
Another nice example of how i’m working together with Wikipedians: a user asked for photos of the Wire of Death, a lethal electric fence on the Dutch-Belgian border during the First World War. Spaarnestad Photo, that resides in the building of the National Archive, has the copyright on seven of these photographs. I asked if they would be willing to release these photos (in low resolution) under a CC-BY-SA license, and fortunately they did. I don’t the think the user would have had any success without an intervention by somebody who worked next door to the Spaarnestad managing director.
Another way for Wikipedians to explore the collection of the KB & NA will be during the Wikimedia New Year’s Reception, which will be held at the institutions on January 18th 2014. A nice time to present some of the results of the WiR program as well.
The future
For now i’m focusing on finishing the last course for employees. Where the last three months of 2013 were about looking inside, 2014 will be about looking behind the walls of the archive and library. I’ll be organising edit-a-thons for anyone that wants to use the collections of the KB and NA to expand Wikipedia articles. I will also be coordinating uploads of media files to Wikimedia Commons, and maybe even some data dumps for Wikidata.
Map from the journal of Abel Tasman from the National Archive (number 1.11.01.01, inv.nr. 121)
The biggest event will be something i’ve tentatively called Wiki Loves Maps: a full month of events dedicated to maps, cartography and the historic places and events that are depicted on those maps.
The KB and NA have wonderful highlights in their collection, but for this project i want to look outside The Hague towards my peers. During my two months of residency three more Dutch Wikipedians in Residence have been announced: Hans Muller and Arie Sonneveld for the Scientific Library Working Group (WSWB) and Sandra Fauconnier for the Tropenmuseum and Academic Heritage Foundation (Stichting Academisch Erfgoed). All of their institutions have wonderful maps as well, and it would be silly not to use the opportunity of four WiR’s at the same time to organise something together. Besides that, the Dutch bookweek in March has travel as its theme this year, so that seems like a natural fit.
If you have any comments or remarks please share them (anonymously) in the comments. And share this article on Facebook, Twitter, or your favourite social network.
You might know this problem: for some reason Akismet didn’t quite work and now you have this old WordPress blog with thousands of spam comments. Of course, you could try the ‘Check for spam’ button in the comments panel, but that might not work for every comment.
So here’s a little guide to help you fix this problem easily using phpMyAdmin (which is probably already installed on your server) and some SQL magic.
Warning: you want to make a backup of your database first before using this guide, in case you accidentally delete more stuff than you want.
Okay, let’s get started! First, log into phpMyAdmin and locate the WordPress database (it’s probably called ‘wp’ or ‘wordpress’). From the left-hand column select the ‘wp_comments’ table, and then on the top, click the ‘Search’ button.
In this new screen look for the ‘comment_author_url’ field. From the ‘operator’ dropdown there select the ‘LIKE %…%’ option and enter ‘http’ in the value field. Now press search.
In my experience virtually all spam uses the ‘website’ field to link to their spam site. This list might also include valid comments. If that’s the case but you’re sure you haven’t had a lot of comments in the post few months you could check for the last ‘valid’ comment, note the ‘comment_ID’ and add that to the search as well (use the > operator in the search tab). Otherwise..it’s either bad luck for those people or you need to weed out all the valid comments by hand…
So, now you’ve got this whole list. To delete them simply press the ‘edit’ link underneath the SQL statement on top of the page. It will probably look something like this:
SELECT * FROM `wp_comments` WHERE LIKE '%http%'
Change the SELECT * into DELETE so it looks like this:
DELETE FROM `wp_comments` WHERE LIKE '%http%'
You’ll get a warning because you’re gonna delete stuff. Press OK and all those pesky comments will be gone!
If this guide was helpful to you feel free to share it on Twitter or Facebook or leave a comment here.
Here’s an interesting problem i recently encountered.
I’ve got a site using Require.js. I’m loading an external library that doesn’t use Require. This library loads some external dependencies, one of them being Mustache.js. This library doesn’t use Require for loading dependencies, but a simple system of inserting <script> tags with a src tag.
See the problem? Because i’m using Require this module exports itself using the define() call. However the external library i’m using expects its to be in global scope so doing
Mustache.render()
Won’t work.
Actually, for some weird reason (maybe something with lazy loading and evaluating JS?) this seems to work in Chrome, but on the iPad it fails.
So, who’s wrong here? Should the UMD definition be redefined to always export a global variable? Or is the external library just ‘doing it wrong’ and should they not use an external library like this?
Unfortunately there’s no clearcut answer to that. For now, i see three different ways to fix this.
Load the UMD module before Require in a script tag
So, do something like this:
<script src="http://example.com/mustache.js"></script>
<script src="http://example.com/require.js"></script>
<script>
// Mustache will be available before Require, and will attach itself
// to the global scope.
var html = Mustache.render();
</script>
Load the UMD module with Require, but re-attach to the global scope
This is a bit hacky, but maybe a better solution than having a seperate script tag.
// First load the UMD module dependency and attach to global scope again
require(['/example/mustache'], function(Mustache) {
window.Mustache = Mustache; // re-attach to global scope
// Now load the problematic module
require(['/example/module'], function() {
// This module can use Mustache as a global variable
});
});
Change the UMD definition
I guess this is only interesting if the problematic dependency is also under your control, but you could change the UMD definition to something like this:
Apparently defining ‘dynamic’ content in a class doesn’t work.
The solution: either add the array in the constructor:
class Say {
private $fns;
function __construct() {
$this->fns = [
"hello" => function($name, $name2 = false) {
echo empty($name2) ? "Hello $name" : "Hello $name and $name2";
},
"bye" => function($name) {
echo "Bye $name";
}
];
foreach ($this->fns as $fn) {
call_user_func_array($fn, func_get_args());
}
}
}
$say = new Say("foo");
$say = new Say("foo", "bar");
Or (slightly better in terms of readable code) define the functions in the class and reference them from the array
class Say {
private $fns = ['hello', 'bye'];
function __construct() {
foreach ($this->fns as $fname) {
$fn = array($this, $fname);
call_user_func_array($fn, func_get_args());
}
}
public function hello($name, $name2 = false) {
echo empty($name2) ? "Hello $name" : "Hello $name and $name2";
}
public function bye($name) {
echo "Bye $name";
}
}
$say = new Say("foo");
$say = new Say("foo", "bar");
Et voila, a nice way to write flexible PHP!
BONUS: if you don’t want to write out all the methods by hand in the $fns array you could use this dirty trick to get all function names in the class without the ‘magic’ methods like __construct and __autoload:
class Say {
function __construct() {
$fnames = array_filter(get_class_methods($this), function($name) {
return $name[0] != "_";
});
foreach ($fnames as $fname) {
$fn = array($this, $fname);
call_user_func_array($fn, func_get_args());
}
}
public function hello($name, $name2 = false) {
echo empty($name2) ? "Hello $name" : "Hello $name and $name2";
}
public function bye($name) {
echo "Bye $name";
}
}
$say = new Say("foo");
$say = new Say("foo", "bar");