Ga even met me mee, bijna precies twintig jaar terug in de tijd. We gaan naar dinsdag 16 december 2003. Nederland wordt sinds een half jaar geregeerd door het tweede kabinet-Balkenende. Saddam Hoessein is net opgespoord in Irak. En we weten nét wie er na Willem-Alexander ons staatshoofd zal zijn: het is een meisje.
Ik was toen twintig jaar oud, woonde net een paar maanden op kamers en schreef voor de inmiddels ter ziele gegane muzieksite tinymixtapes.com. En voor die site moest ik, zoals alle recensenten, een lijstje indienen met wat volgens mij de beste muziekalbums van dat jaar waren.
Ik had toen uiteraard geen idee dat ik twintig jaar lang ieder jaar mijn Lijstje zou maken. Want ja, onze kroonprinses heeft de mooie leeftijd bereikt van twintig, en mijn Lijstje dus ook.
Ergens afgelopen zomer realiseerde ik me dat het deze winter zo ver zou zijn. En wat is er nou een betere manier om dat te vieren dan alle albums die ik de afgelopen twintig jaar in mijn Lijstjes heb opgenomen opnieuw te luisteren en een lijst-der-lijsten te maken?
Dus daar ben ik afgelopen zomer mee begonnen. Het waren er 400. Elke dag luisterde ik één of twee van die albums terug. In de afgelopen weken waren het er wat meer dan dat (en niet altijd van het begin tot het einde, want ik heb ook een leven). Ik voegde ook nog wat albums toe aan mijn longlist die oorspronkelijk niet in een van mijn lijstjes hadden gestaan.
De longlist van 400 werd een shortlist van 130. En toen begon het grote husselen en dubben. Is My Beautiful Dark Twisted Fantasy van Kanye West een beter album dan Silent Shout van The Knife? Kan ik het maken om drie platen van Sufjan Stevens op te nemen bij de bovenste 11? Is I Love You Honeybear van Father John Misty bij nader inzien toch behoorlijk overschat en vrij matig? Het antwoord op die vragen weet ik inmiddels (het is drie keer ja).
Wat viel me op na 400 albums te hebben teruggeluisterd? Dat (en nu ga ik denk ik vrij hard tegen bepaalde schenen aantrappen) het toch vrij vaak gaat om individuele nummers en minder om het hele album. In 2003 waren er nauwelijks goede (legale) manieren om veel nieuwe muziek te luisteren. Dat kwam pas in 2010, toen Spotify in Nederland werd geintroduceerd. Streaming heeft niet alleen de manier waarop we muziek luisteren veranderd. Het heeft ook veranderd hoe we naar muziek luisteren. Nummers kom je tegen in een playlist, zoals in je Discover Weekly. Streaming heeft het idee van een album als meer dan de som der nummers aan gruzelementen geslagen. Al was het maar omdat je bij elk nummer in Spotify naast de titel ook ziet hoe vaak het is geluisterd. Aantal streams als een essentieël onderdeel van een luisterervaring.
Het interessante is dat dit dus ook retroactief werkt: als ik nu naar oudere albums luister dan zie ik dat toch veel meer als een verzameling nummers. Eigenlijk heel erg hoe dat werkte in de jaren zestig, tot de Beatles daar met Sgt. Pepper een einde aan maakten. Het idee van het album als een geheel is dus echt iets tijdelijks geweest. Het is grappig dat muzieksite Pitchfork dat in 2003, datzelfde jaar dat ik mijn eerste Lijstje schreef, precies al voorspelde, in de recensie voor Radiohead’s OK Computer (even helemaal naar beneden scrollen). Iets waar ze in 2017 ook nog op terugblikten.
Dus waar beoordeel je dan een album op? Wat mij betreft is dat dus eigenlijk heel simpel: in hoeverre er genoeg goede nummers op staan. Ik merkte tijdens het luisteren dat het een goed criterium was als ik eigenlijk niet naar het volgende album doorwilde (zoals ik al meldde moest ik er 400 luisteren), maar wilde blijven luisteren. Ook een goed criterium: of ik me de nummers überhaupt kan herinneren: een “oh ja” is ook een bonuspunt. Of het memorabel is.
Dan is er ook nog zoiets als persoonlijke smaak. Je zou een goed argument kunnen maken dat je het beste zo’n lijst kan zien als de platen waar je zelf het meeste mee hebt. En dat het sowieso zinloos is om er een volgorde in aan te brengen.
Daar ben ik echter te neurotisch voor. Een lijstje dient voor mij te beginnen bij 1, met op die plek de beste, op 2 de enabeste, etcetera.
Waar ik verder na 400 albums hélemaal geen zin meer in had is om gevatte stukjes te schrijven per album. U moet het maar gewoon doen met de namen en de volgorde. Als u toch nog iets van een handleiding wilt: scroll er gewoon een beetje doorheen, en zoek op wat u niet kent, of wat u prikkelt, of wat u herkent maar al lange tijd niet meer hebt geluisterd.
Hier zijn mijn honderd beste albums van de afgelopen twintig jaar:
Sufjan Stevens – Illinois (2005)
The Field – From Here We Go Sublime (2007)
Kanye West – My Beautiful Dark Twisted Fantasy (2010)
The Knife – Silent Shout (2006)
Joanna Newsom – Ys (2006)
Antony and the Johnsons – I Am a Bird Now (2005)
Sufjan Stevens – Carrie & Lowell (2015)
Arcade Fire – Funeral (2004)
Joanna Newsom – Have One On Me (2010)
Songs:Ohia – Magnolia Electric Co. (2003)
Sufjan Stevens – The Age of Adz (2010)
The Fiery Furnaces – Blueberry Boat (2004)
Max Richter – The Blue Notebooks (2004)
Wrens – The Meadowlands (2003)
Wolf Parade – Apologies to the Queen Mary (2005)
Radiohead – In Rainbows (2007)
The Rapture – Echoes (2003)
Animal Collective – Merriweather Post Pavilon (2009)
Wolf Parade – At Mount Zoomer (2008)
Big Thief – Dragon New Warm Mountain I Believe in You (2022)
For Those I Love – For Those I Love (2021)
William Basinski – The Disintegration Loops (2003)
My Bloody Valentine – m b v (2013)
Lil Wayne – Tha Carter III (2008)
Jai Paul – Leak 04-13 (Bait Ones) (2013 / 2019)
The Weeknd – House of Balloons (2011)
Clap Your Hands Say Yeah – Clap Your Hands Say Yeah (2005)
M.I.A. – Arular (2005)
Nala Sinephro – Space 1.8 (2021)
Jenny Hval – Classic Objects (2022)
Telefon Tel Aviv – Immolate Yourself (2009)
Tame Impala – Currents (2015)
Kanye West – Yeezus (2013)
Cloud Nothings – Here and Nowhere Else (2014)
Jockstrap – I Love You Jennifer B (2022)
Slowdive – Slowdive (2017)
Death Grips – The Money Store (2012)
David Bowie – Blackstar (2016)
Lindström – Where You Go I Go Too (2008)
Toumani Diabaté – Toumani & Sidiki (2014)
Fuck Buttons – Tarot Sport (2009)
Owen Pallett – Heartland (2010)
Jay-Z & Kanye West – Watch The Throne (2011)
Beyoncé – Renaissance (2022)
The Weather Station – Ignorance (2021)
Ana Roxanne – Because of a Flower (2020)
Sally Shapiro – Disco Romance (2007)
Common – Be (2005)
Thom Yorke – The Eraser (2006)
Burial – Untrue (2007)
Kali Uchis – Isolation (2018)
Run the Jewels – Run the Jewels 2 (2014)
BEA1991 – Brand New Adult (2019)
Oneohtrix Point Never – Replica (2011)
Macintosh Plus – Floral Shoppe (2012)
Blur – Think Tank (2003)
Jlin – Dark Energy (2015)
Huerco S. – For Those Of You Who Have Never (And Also Those Who Have) (2016)
Daft Punk – Random Access Memories (2013)
Das Pop – The Human Thing (2003)
Radiohead – A Moon Shaped Pool (2016)
Big Thief – U.F.O.F (2019)
Alvvays – Blue Rev (2022)
Hydrogen Sea – Automata (2019)
dEUS – Pocket Revolution (2005)
Low – HEY WHAT (2021)
Blonde Redhead – 23 (2007)
Eefje de Visser – Bitterzoet (2020)
Alex G – God Save the Animals (2022)
Run the Jewels – Run the Jewels 3 (2017)
Spoon – They Want My Soul (2014)
Julia Jacklin – Don’t Let the Kids Win (2016)
Bon Iver – Bon Iver (2011)
Oneohtrix Point Never – Returnal (2010)
Antony & The Johnsons – The crying light (2009)
Future Islands – Singles (2014)
Courtney Barnett – Tell Me How You Really Feel (2018)
Cut Copy – In Ghost Colours (2008)
Björk – Utopia (2017)
Arooj Aftab – Vulture Prince (2021)
The Whitest Boy Alive – Rules (2009)
Gorki – Voor Rijpere Jeugd (2008)
Natalie Prass – Natalie Prass (2015)
CHVRCHES – The Bones of What You Believe (2013)
Amy Winehouse – Back To Black (2006)
Caribou – Our Love (2014)
Julia Jacklin – Crushing (2019)
Deerhunter – Halcyon Digest (2010)
Bauer – Baueresque (2004)
Spoon – Hot Thoughts (2017)
Big Thief – Two Hands (2019)
The Walkman – Lisbon (2010)
Joanna Newsom – Divers (2015)
Deserta – Black Aura My Sun (2020)
Thom Yorke – ANIMA (2019)
The Field – Cupid’s Head (2013)
araabMUZIK – Electronic Dream (2011)
Weyes Blood – Titanic Rising (2019)
Phoebe Bridgers – Punisher (2020)
Grizzly Bear – Shields (2012)
In deze lijst kwamen bewust geen albums voor van dìt jaar (is het dan eigenlijk wel een lijst van de afgelopen twintig jaar?). Gelukkig hoeft u niet lang te wachten om te weten wat de beste albums van dit jaar waren, want over twee weken, op eerste Kerstdag krijgt u mijn twintigste Lijstje met de beste albums van 2023.
Ik las de afgelopen tijd het boek Four Thousand Weeks van Oliver Burkeman. De ondertitel is Time management for mortals. Eigenlijk is dat een wat misleidende titel. Ik dacht dat dit een boek zou zijn over hoe je efficiënt je tijd kan indelen, en dingen voor elkaar kan krijgen. Een soort van Gettings Things Done (David Allen, 2002) of Building a Second Brain (Tiago Forte, 2022).
Maar dat is Four Thousand Weeks hélemaal niet. Het gaat zeker over tijdmanagement, maar dan filosofisch. Burkeman haalt er Heidegger en een hoop andere wijze mensen bij om een heel ander verhaal te vertellen, namelijk over hoe we onszelf in de hedendaagse kapitalistische efficency-maatschappij voor de gek houden dat we eindelijk aan de dingen die we écht willen toe gaan komen als we onze tijd maar efficiënt genoeg indelen.
Burkeman noemt dit de paradox van de beperking: hoe meer je tijd onder controle probeert te krijgen, hoe stressvoller en frustrerend je leven wordt. Die paradox is nog veel evidenter geworden door het internettijdperk. Dankzij de moderne techniek kunnen we onze tijd een stuk efficiënter gebruiken, maar alle tijd die daardoor vrijkomt wordt gevuld met eindeloos veel nieuwe keuzes. Denk maar aan e-mail: je kunt veel meer berichten lezen en beantwoorden dan voorheen, maar je krijgt ook veel meer berichten dankzij datzelfde medium.
Er zijn eindeloos veel keuzes bijgekomen, maar de tijd die we hebben is nog steeds beperkt. Daar komen die 4000 weken vandaan (het totaal aantal weken dat een gemiddeld mensenleven kent). De filosoof Heidegger betoogde dat we die beperkte tijd niet eens hebben, we zijn die tijd. Dat is namelijk dat wat ons mens maakt: al die kleine keuzes die we maken waardoor een eindeloze stroom aan mogelijke levens niet gebeurt.
En dat kan dan ook verlammend werken. Want in die zee van keuzes die we kunnen maken is het verleidelijk om “alle opties open te houden”. De relatie die je mogelijk kan hebben, het meesterwerk dat je mogelijk kan creëren, de ideale baan die je kan hebben; wat je in je hoofd voorstelt is eindeloos veel beter dan die onhandige, faalbare en gelimiteerde werkelijkheid.
Volgens Burkeman zit juist daarom de betekenis van het leven in het maken van keuzes, ook als je er niet zeker van bent. Dat noemt hij ook wel the joy of missing out (in plaats van the fear of missing out). Als je nooit zou hoeven te kiezen wat je moet missen in je leven dan betekenen je keuzes ook niks. “Alle opties open houden” is een manier om te veinzen dat je controle hebt in plaats van dat je jezelf committeert aan dingen die pijn, ellende en onzekerheid kunnen veroorzaken.
Daar zit dan ook gelijk een andere gekke paradox in die ik zelf vaak ben tegengekomen. Namelijk dat je dingen die belangrijk zijn uitstelt. Of waar je geen zin in hebt. Wat ogenschijnlijk heel gek klinkt. De dingen die je belangrijk vindt zou je toch juist leuk moeten vinden? In plaats daarvan zoek je afleiding en zit je weer te scrollen door het nieuws of op een sociaal medium. Burkeman beargumenteert dat die afleidingen (zoals social media) niet de reden zijn van de afleiding, maar dat het de plekken zijn waarin we vluchten omdat we niet willen aanvaarden dat er limieten zijn, dat wat je gaat maken niet hetzelfde gaat zijn als wat er in je hoofd zit.
Zolang je jezelf voor de gek blijft houden dat de echte betekenis van je leven, en die mooie momenten allemaal in de toekomst liggen dan hoef je jezelf ook niet te confronteren met wat er echt gaat gebeuren: je leven werkt niet toe naar een zinvol moment van waarheid waarop je alles opeens zal begrijpen. Je leven werkt toe naar het onvermijdelijke moment van de dood.
Dat klinkt nogal donker. En wellicht dat je veronderstelt dat je dus continu bezig moet zijn met dat alles betekenis moet hebben in het leven, omdat het maar zo kort is en elke keuze definitief is. Burkeman betoogt dat de enige manier om daar mee om te gaan precies het omgekeerde is: het mens-zijn is een pijnlijke ziekte, maar het is alleen ondragelijk als je het idee hebt dat er een medicijn voor is. Uiteindelijk maakt het allemaal niks uit: we gaan allemaal dood, en over duizend jaar is alles wat je ooit hebt gedaan vergeten door iedereen. Maakt het dan uit dat je jezelf nu continu druk maakt over de vraag of je wel met betekenisvolle dingen bezig bent?
Niet alles hoeft betekenis te hebben. Ik ben blij dat het in Nederland (in tegenstelling tot de Verenigde Staten) normaal is dat mensen op vakantie gaan omdat ze dat leuk vinden, en dat niet hoeven te verantwoorden met zinnen als: “ik ga op vakantie zodat ik straks beter uitgerust mijn werk kan doen”. Vakantie kan toch ook gewoon leuk zijn en niet als doel hebben dat je jouw werk beter doet? En hetzelfde geldt voor hobbies. Als je het leuk vindt om te voetballen, te zingen of te acteren hoef je toch niet net zo goed als Messi, Adele of Ryan Gosling te worden? Hoe erg is het als je veertig jaar tennis speelt en er nooit echt goed in wordt? Het kan toch ook gewoon leuk zijn om een balletje te slaan en daarna een biertje te gaan drinken?
En ook daar ligt denk ik de kern van veel van de problemen die Burkeman aanstipt in onze moderne maatschappij: we zijn veel te veel met onszelf bezig. Nelson Mandela zei ooit dat de betekenis van ons leven bestaat uit het verschil dat we maken in de levens van anderen. Het is een cliché voor op een tegeltje, maar waar is het wel. Tijd is niet iets om te sparen, maar om te delen.
Jaren geleden was ik in Kaapstad. Ik liep over een lokale markt, waar een grote bak stond met koelkastmagneten. Op de magneten stonden in sierlijk schrift tenenkrommende gemeenplaatsen als ‘Home is where the heart is’, ‘Live, laugh, love’ en ‘Be a warrior, not a worrier’. Een Amerikaanse toerist pakte een van de magneetjes op, inspecteerde ‘m en zei met veel overtuiging: “Oh my god, that’s so profound”.
Ik moest daar met mijn reisgezelschap hartelijk om lachen. Want die wijsheden zijn misschien wel waar, ze zijn ook zo ontzettend algemeen.
Begin dit jaar realiseerde ik me dat ik in juni veertig zou worden. “Het is maar een getal” is ook zo’n fraaie gemeenplaats, maar het doet me wel wat. Je kijkt terug: wat heb ik allemaal bereikt? Heb ik alles wel gedaan wat ik wil doen, nu dat ik “op de helft” ben? Wat heb ik eigenlijk geleerd?
Begin dit jaar begon ik vast te leggen wat ík heb geleerd. Geen algemene theorie van alles. En zeker niet consistent, dat is het leven ook niet. Een persoonlijke lijst dus, of een soort handleiding voor mezelf.
Veertig dingen dus, die ik heb verdeeld in vier onderdelen: algemene tips van praktische aard, hoe je samen moet leven, hoe je creëert en tenslotte hoe je jezelf leert kennen.
Hopelijk heeft u er wat aan. Vermakelijker en interessanter dan “home is where the heart is” is het zeker.
Met hartelijke dank aan LotteB, LotteM, Jutta, Frans, Oliver, John, Trudi en alle anderen die versies van deze lijst hebben gelezen en van commentaar hebben voorzien.
1. Neem een leeg waterflesje en een klein tasje mee als je gaat vliegen. Het flesje vul je na de douane zodat je geen water hoeft te kopen. In het kleine tasje doe je de dingen die je nodig hebt in je stoel zodat je niet je hele tas hoeft te pakken als je iets nodig hebt.
2. Als je iets nodig hebt van mensen en ze een bericht stuurt dan reageren ze óf binnen 24 uur óf niet. Als je iets gedaan wilt krijgen moet je mensen na 48 uur er weer eens aan herinneren. Maar eigenlijk moet je gewoon bellen.
3. Wanneer je iets niet moet vergeten (bijvoorbeeld een brief), leg het dan neer op een plek waar je het tegen gaat komen, zoals bij je sleutelbos of op je fietszadel.
4. Je telefoon heeft twee kanten. Draai het scherm naar beneden en betreed de zone der rust.
5. Als je elke dag gefrustreerd zit te schrijven met een pen die het slecht doet gooi dan in godshemelsnaam die pen in de prullenbak en koop een goede. Ja, dit is een metafoor. Nee, het is niet romantisch om met een kutpen te schrijven.
6. Mijn vader zei altijd: leg dingen terug op dezelfde plek, dan raak je ze nooit kwijt. Dit klopt.
7. Adriaan van Dis zei ooit: “Beter één dag als een rijkaard geleefd en vijf dagen als monnik, dan zes dagen als een voorzichtige boekhouder.”. Trakteer jezelf en doe niet te moeilijk over geld als je het hebt.
8. Leer Excel / spreadsheets. Mét formules. SUM, VLOOKUP en COUNT zullen je leven veranderen.
9. Als je denkt: “dit moet ik vastleggen” doe het dan nu. Als je denkt: “dat doe ik later wel” vergeet je het of ben je te laat.
10. Schaam je niet om (computer)dingen op te zoeken. Ik programmeer al 30 jaar en ik Google nog steeds elke dag twintig keer de meest basale dingen.
11. Niet iedereen kan samen. Als een relatie (professioneel of persoonlijk) moeilijk gaat kan het zijn dat het gewoon niet klikt. Het betekent niet dat de ander gek is of een slecht mens.
12. De dingen die jij raar aan jezelf vindt zijn voor anderen een reden je te zoenen.
13. Voel geen enkele loyaliteit bij mensen die jou slecht behandelen en behandel ze dus ook zo.
14. Zie de mensen die je liefhebt vaak, het kan zomaar de laatste keer zijn.
15. De wereld kent een chronisch gebrek aan luisteraars. Luisteren is niet je mond houden maar vragen stellen en antwoorden herformuleren zodat je snapt (en laat blijken) wat de ander bedoelt. En niet elke vraag die mensen stellen vraagt om een oplossing. Soms willen ze gewoon hun verhaal kwijt omdat ze zich kut voelen of eenzaam zijn.
16.Awkwardness (sociale ongemakkelijkheid) is alomtegenwoordig in het leven. Wen er maar aan.
17.If it is to be, it’s up to me. Je kan nog zo goed samenwerken, anderen gaan jouw problemen niet voor je oplossen. Als je iets echt graag wilt, doe het dan.
18. Als mensen onredelijk boos worden of raar gedrag vertonen ligt dat bijna altijd aan hen en niet aan jou. Heb desondanks compassie voor ze. Iedereen heeft wel eens een slechte dag.
19. Als je de hele tijd tegen anderen klaagt over je partner (of vice versa) dan moet je jezelf afvragen of die partner nog wel de juiste voor je is.
20. Niet alles hoeft een reden of verklaring te hebben. Dingen zijn vaak gewoon hoe ze zijn. Dat is alleen lastig te accepteren.
21. Spontaan succes bestaat niet. Alles hangt aan elkaar van geluk en (meestal) veel werk. En als je denkt: “hoe hebben ze dit gedaan, dat lijkt me heel veel werk” is het antwoord meestal: heel veel werk.
22. Er zijn (bij voorkeur op tijd) en beginnen is de helft van het werk. Volhouden de andere.
23. Mensen “kijken” niet door slechte presentaties heen. Je idee / project / werk kan nog zo fantastisch zijn, als je het slecht communiceert gaan mensen er echt niet de waarde van inzien. Andersom is ook vaak waar: goed verpakte troep wordt snel geloofd.
24. Niet alles hoeft iets op te leveren. Je kan ook gewoon dingen doen omdat je het leuk vindt. Niet alles hoeft te worden geofferd op het altaar der efficiëntie en productiviteit.
25. Wie een berg wil beklimmen begint met een heuvel. Als je iets nieuws wilt maken begin dan klein, met een prototype, experimentje of testje.
26. Aannames zijn de oorzaak van alle misverstanden en ellende. Als je denkt dat je iemand snapt, vertel dan jouw interpretatie en check of het echt klopt.
27. Liefdeloos dingen doen is een zonde. Als iets liefdeloos is gedaan voel je dat. Of het nou de bediening van het restaurant is of de NPO Start-app.
28.Underpromise and overdeliver. Er zijn wel meer van dit soort wijsheden, maar deze klopt echt.
29. Deel je werk vroeg en met velen. Je kwetsbaar opstellen is een deugd. Hoe meer ogen, hoe beter je werk wordt.
30. Wees selectief in waar je echt werk van wilt maken, anders ben je overal boos op en bereik je nooit wat.
31. Mensen bagatelliseren hun gevoelens door ze te meten aan die van een ander. Maar gevoelens zijn geen wedstrijd. Iedereen is ongelukkig op z’n eigen speciale manier.
32. Als je vastlegt wat je doet en hoe je jezelf voelt (in een dagboek, gedicht, muziek, welke vorm dan ook) ga je patronen zien. Dat geeft inzicht en laat zien dat het beter met je gaat dan je denkt.
33. Als je jezelf slecht voelt check dan of je wel genoeg slaapt, gezond eet, beweegt en andere mensen ziet. Ja, dit is geen revelatie. Ja, het is toch belangrijk.
34. Wijsheden als “Leer van jezelf te houden” of “Leer jezelf kennen” moet je actief en fysiek in de praktijk brengen. Dus als je jezelf wil leren kennen ga je maar drie weken alleen op groepsvakantie naar Vietnam. Want als dingen alleen in je hoofd blijven gebeurt er niks.
35. Stoppen is makkelijker dan je denkt. Dat geldt ook voor een vaste baan. Je geeft niet op en laat niemand in de steek. Je bent gewoon sterk genoeg om afscheid te nemen.
36. Je buik heeft gelijk. (Het gevoel in die buik, niet je honger).
37. Het valt bijna altijd mee. Het ergste dat er kan gebeuren is dat het mislukt.
38. Ja, het komt van je ouders.
39. Je weet best wat goed voor je is, maar je doet het niet omdat je jezelf voor de gek houdt.
40. Hoe ouder je wordt hoe minder schroom en schaamte je hebt. Dit is (meestal) goed.
Heeft u zelf ook een ding dat u heeft geleerd? Of bent u het volstrekt oneens met een van deze uitspraken? Of heeft u een aanvulling? Laat het me weten en laat een comment achter beneden.
Panoramafoto van de deelnemers. 📷 Fuzheado / CC-BY-SA 4.0
In het weekend van 19, 20 en 21 mei was ik aanwezig bij de Wikimedia Hackathon in Athene. Zo’n 200 mensen die zich bezighouden met de Wikimedia-projecten (zoals Wikipedia) kwamen drie dagen bij elkaar om samen dingen te bouwen, te praten, discussiëren en bier te drinken. Het was de eerste keer sinds 2019 dat het evenement weer fysiek plaatsvond. Alleen al daarom een goede reden om weer eens te gaan. Zo ontmoette ik bijvoorbeeld Annie Rauwerda (van het social media-fenomeen Depths of Wikipedia), met wie ik eerder een presentatie maakte voor de Wikicon van 2021.
De hackathon vond plaats op Technopolis, een cultureel park op het voormalige terrein van een gasfabriek, vergelijkbaar met het Westergasterrein in Amsterdam. De locatie was prachtig, maar helaas waren er op vrijdag en zaterdag wel de hele dag soundchecks en optredens van respectievelijk een concert voor en van mensen met een beperking (“Cool Crips”, ja echt) en een indiepopband. Dat werd gelukkig gecompenseerd door het geweldige Griekse eten. Wist u overigens dat de Grieken de meeste olijfolie consumeren ter wereld? Misschien dat het daarom zo lekker is.
Depictor
Wat doe je zoal op zo’n hackathon? In 2018 was ik de laatste keer bij een Wikimedia Hackathon (die was toen in Barcelona). Ik merkte toen dat het weinig zin heeft om veel plannen te maken. Voor je het weet heb je een uur lang een interessant gesprek of ben je iets heel anders aan het uitzoeken dan dat je oorspronkelijk had bedacht.
Mijn enige “plan” was om “iets” te doen met Depictor, mijn tool om gestructureerde metadata toe te voegen aan de plaatjes op Wikimedia Commons. Die tool bestaat nu bijna twee jaar en heeft meer dan een miljoen edits opgeleverd (waaronder een half miljoen van een zéér actieve Poolse gebruiker). Tijdens de hackathon paste ik het tooltje aan zodat de plaatjes een stuk sneller laden. Mijn mede-hackathonner Siebrand (tevens trouwe lezer van deze nieuwsbrief) werd daar zo door gestimuleerd dat hij de afgelopen week meer dan 11.000 edits maaktte. Voor de toekomst ben ik van plan Depictor uit te breiden met meer datasets. Ik kreeg via Wikimedia-medewerker Matthias een dataset met 87 miljoen mogelijke “kandidaten”, dus Siebrand en mijn Poolse gebruiker zijn de komende tijd nog niet uitgedepictored.
The intangible
Nu we het toch over Siebrand hebben, hij organiseerde de showcase van de hackathon. Iedereen mag dan presenteren wat ze afgelopen dagen hebben gebouwd. Een nieuw onderdeel van die showcase, dat ik half samen met Siebrand bedacht, was iets dat hij the intangible (“het ontastbare”) noemde: wat waren de dingen die mensen hadden meegemaakt die zich niet lieten vertalen in geschreven regels code of opgeloste bugs? Het zorgde voor een rijke stroom aan prachtige anekdotes, verhalen en complimenten. Er was bijvoorbeeld iemand die vertelde hoe dit zijn eerste Wikimedia-bijeenkomst ooit was en hoe fijn hij door iedereen was ontvangen. Ik kan iedereen aanraden die een dergelijke conferentie organiseert om ook een intangible presentatie te doen.
Naast het coden waren er ook lezingen, waaronder eentje die ik zelf hield. Ik vertelde vooral over wat ik allemaal heb geleerd in de afgelopen negen jaar als tool developer. U kunt hier de notities teruglezen (er zijn geen video-opnames gemaakt).
Na die lezing werd ik aangesproken door een studente kunstgeschiedenis van de Ionische Universiteit op Corfu. Of ik nog tips had hoe zij als Wikipedian in Residence in een museum aan de slag kon (ik was zelf in 2013 de eerste Nederlandse Wikipedian in Residence). Ik drukte haar op het hart om vooral te kijken of ze binnen kon komen via de afdeling registraties of datamanagement. Informatieprofessionals snappen Wikipedia vaak beter dan curatoren of de directie.
AI
Een onderwerp van veel lezingen was hoe de gemeenschap om moet gaan met de snelle opkomst van AI. De data van Wikipedia wordt veel gebruikt om AI-modellen te trainen, maar ironisch genoeg doet de gemeenschap er zelf nog vrij weinig mee. Betrouwbaarheid is één van de belangrijkste pijlers onder de projecten. Dat laat zich lastig combineren met taalmodellen die nog wel eens zelf bronnen “fabriceren”. Een taalmodel dat alléén is gevoed met Wikimedia-content is helaas geen optie, daarvoor is zelfs die enorme hoeveelheid data niet voldoende.
Kansen zijn er echter genoeg. Bijvoorbeeld het samenvatten van lange stukken tekst. Of dat een goed idee is bij Wikipedia-artikelen weet ik nog niet. Maar voor de ellenlange discussies kan het mogelijk heel interessant zijn. Discussies op de encyclopedie hebben regelmatig de lengte van een universiteitsscriptie, als een AI dat een beetje zou kunnen samenvatten zou dat wellicht mijn enthousiasme om meer deel te nemen aan die discussies kunnen bevorderen.
Het ongrijpbare resultaat
Wat levert drie dagen hacken nou op? Dat zijn niet de meetbare resultaten, zoals het aantal geschreven regels code of het aantal gefixte bugs. Het is het feit dat ik na zo’n evenement thuiskom en zin heb om nieuwe dingen te gaan maken. Of terugdenk aan hoe tof het is om met een internationale groep van kennisnerds samen te werken. The intangible dus.
Mijn reis en verblijf werd bekostigd met een beurs van Wikimedia Nederland, waarvoor mijn hartelijke dank.
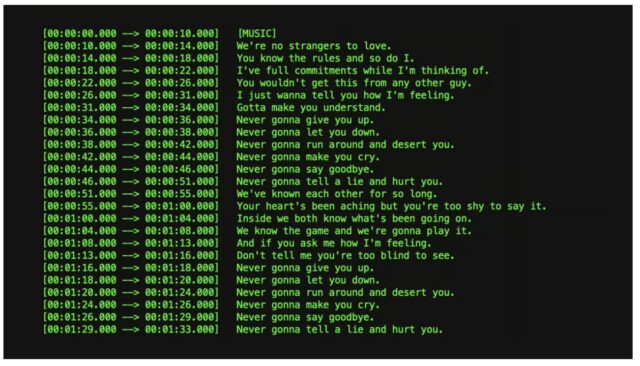
Een AI-technologie waar ik de afgelopen tijd mee speel is Whisper. Dat is een systeem om spraak om te zetten naar tekst, net zoals ChatGPT gebouwd door OpenAI. Het model is getrained op 680.000 uur aan audio, waarvan een derde geen Engels is. Zowel de code als het model zijn open source. Je kunt, net zoals bij ChatGPT, gebruik maken van de API van OpenAI en je audio laten transcriberen (dat kost je zo’n 40 dollarcent per uur).
Ik doe een onderzoek samen met Sahra Mohamed van de Utrecht Data School naar podcasts, en daar willen we graag grote hoeveelheden audio met spraak gaan omzetten naar tekst. Een collega had haar gewezen op Whisper.cpp, een port van de code van Whisper naar C++. De port heeft als voordeel dat het een stuk makkelijker is om het draaiend te krijgen op verschillende machines. Zoals een minicomputer als de Raspberry Pi of een oude smartphone. En natuurlijk zit er ook een financieel en privacy-voordeel aan: je bent niet afhankelijk van een online partij waarvoor je moet betalen en waar mogelijk je data wordt gelekt.
Installeren van die software werkte vrij makkelijk op mijn Macbook. Vervolgens lieten we de software de recentste aflevering van NRC Vandaag transcriberen (dus het omzetten van audio naar tekst). We zagen iets geks in de output: het leek te werken maar alles was geschreven in het Engels. Had NRC Vandaag toevallig een Engelse aflevering vandaag? Nee, blijkbaar vertaalt Whisper als je de instellingen verkeerd hebt staan ook automatisch alles naar het Engels. Bizar. Vooral omdat de teksten in het Engels ook nog eens goed vertaald waren.
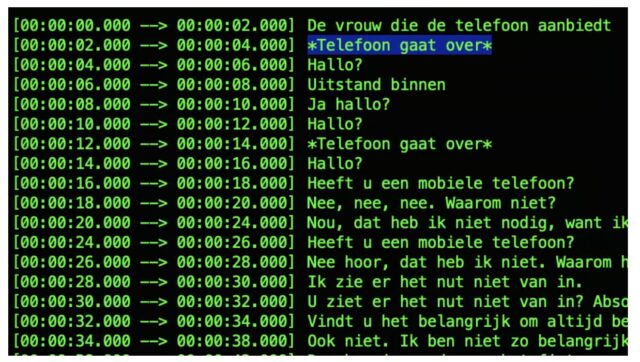
Ook fascinerend was dat Whisper niet alleen spraak omzet in tekst, maar ook geluiden. Dit zijn bijvoorbeeld de eerste paar seconden van dit bekende filmpje van Frans Bromet over de introductie van de mobiele telefoon in Nederland:
*Telefoon gaat over*
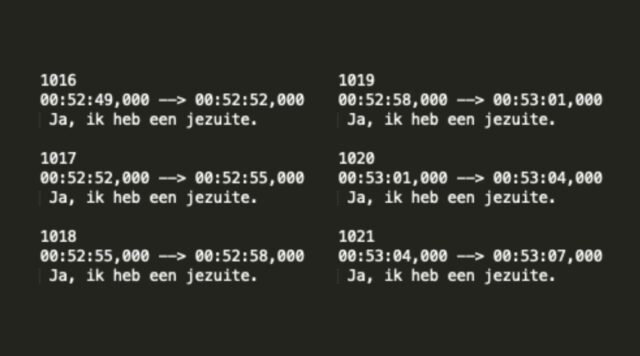
Jezuite
Whisper werkt verbazingwekkend goed, maar het is zeker niet foutloos. Een bekend probleem is dat het model kan gaan ‘hallucineren’: dingen bedenken die er niet zijn. En ik heb ook al een aantal keer gezien dat het model blijft hangen en eindeloos dezelfde zin herhaalt:
Wil je me iets vertellen Whisper?
OpenAI biedt zelf dus geen tool aan om audio om te zetten naar tekst (behalve de API). Er zijn wel organisaties die op de code doorbouwen en er zelf een dienst omheen bouwen, zoals My Good Tape, een Deens initiatief van een lokale digitale krant, waar je met het gratis abonnement 90 minuten per maand kan transcriberen. Podcastnetwerk-lid Michiel testte het uit en meldde me dat er nog wat features misten zoals het kunnen herkennen van verschillende sprekers. Ook is er nog een beperkt aantal exportformats. Dingen die met een concurrent als Amberscript wel kunnen. Maar daar staat tegenover dat de transcriptie dus veel beter is dan die van de concurrent.
ChatGPT is een site waar je kan babbelen met een AI-chatbot. Maar je kan er ook als programmeur mee werken: met behulp van een zogenaamde API kun je de resultaten van ChatGPT gebruiken in je eigen programma.
Het leek me interessant om te kijken of je ChatGPT kon gebruiken om een Mastodonbot te schrijven. Bots waren ooit een typisch Twitter-fenomeneen, maar onder het nieuwe beleid van Elon Musk heeft Twitter de API afgesloten behalve als je minimaal $42.000 per maand betaalt (nee, dat is geen tikfout). Gelukkig is er Mastodon als alternatief, want daar kun je ook gewoon bots voor schrijven. En de API van Mastodon en het aanmaken van een bot blijkt ook nog eens veel eenvoudiger dan bij Twitter. Zeker als je een library gebruikt (ik gebruikte Mastodon.py voor Python) heb je echt letterlijk binnen tien minuten een bot draaiend.
De API van OpenAI voor ChatGPT is zo mogelijk nog makkelijker. Mits je een creditcard hebt kun je gebruik maken van de OpenAI-API en kun je teksten genereren met hetzelfde systeem dat ook door ChatGPT wordt gebruikt. Dat kost wat geld, maar heel weinig: voor 1000 ‘tokens’ (een token is grofweg een woord) betaal je 0,2 dollarcent. Als ChatGPT de complete werken van Shakespeare zou genereren (een stuk waarschijnlijker dan apen op typemachines) zou dat je zo’n 2 dollar kosten.
Voxpopjes
Maar wat laat ik ChatGPT genereren en post ik dan op Mastodon? Ik dacht opeens aan het welbekende voxpopje, de interviewtjes die nieuwsprogramma’s met ‘normale mensen’ afnemen. Met dat formaat heb ik weinig: de meningen zijn vaak zo kort en obligaat dat je net zo goed niks kan zeggen. Eigenlijk net zoals de meeste meningen op Twitter en andere sociale media. Ideaal dus om automatisch te genereren met behulp van AI!
In Python bouwde ik een bot die eerst een ‘karakter’ genereert (‘een boze vrouw van 56 uit Venlo’, ‘een spirituele man van 21 uit Geertruidenberg’). Dat karakter stuur ik dan naar ChatGPT samen met de laatste headline van de NOS en een schrijfopdracht zoals ‘schrijf alles in hoofdletters’ of ‘schrijf cynisch met veel emoji’s’. Zo’n prompt zou dus kunnen zijn:
Doe alsof je blije vrouw van 56 jaar uit Aalten bent en schrijf een tweet waarin je reageert op dit nieuwsbericht: “Laatste coronateststraten GGD sluiten vandaag: ‘geen toegevoegde waarde'”. Begin je zin met ‘ik vind dat’ en maak een tweet van maximaal 250 letters. Schrijf vanuit de eerste persoon. Schrijf niet wie je bent, herhaal geen persoonlijke details zoals je leeftijd en woonplaats. Vertel waarom dit de schuld is van big pharma.
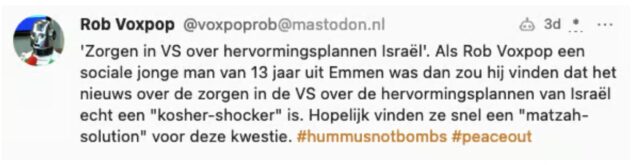
De resultaten zijn vaak hilarisch en net zo zinloos als door mensen gegenereerde voxpopjes:
Het is fascinerend om te zien hoe ChatGPT de creatieve prompts verwerkt. De opdracht is om een tweet te schrijven dus er ontstaan automatisch bizarre hashtags als ‘#hummusnotbombs’.
Interessante toots volgen ook bij de meer extreme schrijfopdrachten als “schrijf cringy met veel afkortingen”:
Wilt u Rob ontmoeten? U vindt hem als @voxpoprob op Mastodon.nl. Rob stuurt vier keer per dag zijn voxpopjes rond de uitzendtijden van de NOS Journaals: om 7 uur ’s ochtends, 12 en 17 uur ’s middags en tijdens het achtuurjournaal.
Dit artikel verscheen eerder in editie #179 van De Circulaire.
Ik las vorige week een interview met en een opiniestuk van Maxim Februari over zijn essay “Doe zelf normaal“, waarin hij bespreekt hoe technologie de democratische rechtsstaat verandert. Februari schrijft dat het best vreemd is dat er zo veel geschreven wordt over de toestand van de wereld, maar zo weinig over de invloed van kunstmatige intelligentie, het internet en algoritmes daarop.
Volgens hem wordt wat ‘normaal’ is steeds meer bepaald door statistiek. Door wat algoritmes uit behavorial data halen. Overheden en beleidsmakers lijken een blind vertrouwen in die data te hebben en schuiven democratische basisprincipes opzij. Data is niet neutraal, en zou geen basis moeten vormen voor wetten en regels. Om te bepalen waar de grenzen van een wet ligt moet je ‘m namelijk overtreden. Februari verwijst naar Rosa Parks, die tijdens de Jim Crow-periode van segregatie in de VS weigerde als zwarte vrouw haar stoel in een bus af te staan aan een witte man. Als niemand ooit de regels overtreedt, worden ze nooit afgeschaft of aangepast.
Big data
Een ander voorbeeld van hoe mensen te veel vertrouwen hebben (mag ik hier het woord ‘oververtrouwen’ munten?) in technologie vond ik in een stuk van Jordan Tigani over big data. Tigani was in het begin van het vorige decennium een van de ontwikkelaars van BigQuery, een technologie van Google waarmee je makkelijk door enorme bergen data kunt zoeken. Big data was destijds echt een modewoord. Bedrijven zouden zoveel data verzamelen dat ze het niet meer met traditonele technologiën konden doorzoeken. Dus werden er data lakes opgezet en ontwikkelaars ingehuurd om al die nieuwe technologiën te implementeren.
Maar wat constateert Tigani tien jaar later? De meeste bedrijven hadden BigQuery helemaal niet nodig. De overgrote meerderheid had minder dan een terabyte aan data. Inderdaad, net zoveel als die externe harde schijf die u ergens in een kast hebt slingeren en waar u hopelijk af en toe een backup op maakt. En al die nieuwe software die nodig was om big data te beheren? Er is nu juist weer een beweging terug naar traditionele relationele databases zoals PostgreSQL, SQLite en MySQL, gecombineerd met cloudoplossingen die goedkoop en snel zijn (een server met een terabyte aan opslag heb je tegenwoordig al voor €100 per maand). Saai en traditioneel is blijkbaar goed genoeg.
S-curve
Misschien zitten we met de huidige digitale technologie wel op het einde van een zogenaamde sigmoïde-curve. De theorie is dat technologie zich traag ontwikkelt, maar dan opeens in korte tijd razendsnel groeit, tot het plafond wordt bereikt in wat mogelijk is. YouTuber Tom Scott publiceerde afgelopen week een videoessay over hoe ChatGPT een stukje code schreef om zijn e-mails te fixen. Die code bleek prima te werken, puur op basis van een paar regels (Engelse) tekst die hij invoerde. Hij vraagt zich af waar we op die S-curve staan met AI. Aan het begin, en moeten de echt grote innovaties nog komen? Of blijven ChatGPT en vrienden een handigheidje? Hoe dan ook ziet hij het als het einde van een tijdperk waarin hij (en ik zelf ook, we zijn van dezelfde generatie) opgroeiden met ‘dit’ internet. Met als belangrijk ijkpunt de introductie van Napster in 1999 (lees vooral dit boek daarover). Dat gooide niet alleen de muziekindustrie overhoop, maar bleek ook een sjabloon voor verandering in heel veel andere sectoren.
De angst die de muziekindustrie had voor Napster zie je nu bij de bedrijven die de afgelopen 25 jaar groot zijn geworden. Google is een goed voorbeeld. Logisch, want de kwaliteit van de zoekmachine is enorm achteruit gegaan. Ik was de afgelopen week bezig een site te ontwikkelen met behulp van WordPress. Een hoop van de “hoe moet dit”-vragen die je als ontwikkelaar constant hebt waren makkelijker te beantwoorden met ChatGPT dan met Google. Bij ChatGPT krijg je direct een antwoord, terwijl je bij Google vaak wordt overspoeld door clickbaity websites die hoog willen scoren. Hoewel die websites niet van Google zijn, vormen ze zich wel naar het Google-algoritme. Je moet je eerst door twintig alinea’s met zinloos gebrabbel worstelen voordat je antwoord krijgt op je vraag. Wellicht een kwestie van tijd voordat ChatGPT-antwoorden ook volzitten met troep, maar ik denk dat dit nog wel even zal duren. Op het moment is Microsoft vooral bezig om te voorkomen dat diens implementatie van ChatGPT in zoekmachine Bing mensen adviseert om te scheiden en te trouwen met een chatbot of gebruikers gaslightdat ze nog in 2022 leven.
Sokken met sandalen
Hoe gaat dit zich allemaal ontwikkelen? Hoe ziet de wereld er over 25 jaar uit, als beleidsmakers en leiders AI gebruiken om delen van onze wetten en regels te genereren? Maximum Februari haalt hoogleraar Mireille Hildbrandt in zijn essay aan, die beargumenteert dat “je de democratie niet kunt computeriseren, maar dat het toch zal gebeuren, omdat te veel mensen denken dat het wel kan.” Ik denk dat zij daar helaas gelijk in heeft.
Natuurlijk vroeg ik ChatGPT ook nog naar welke wetten die zou bedenken. Daar kwam een wet uit die het verbiedt om sokken met sandalen te dragen (“sommige mensen vinden dat onsmakelijk of onmodieus”). Of een regel die voorschrijft dat je je pizza voortaan met mes en vork moet eten.
Ik kijk er alvast naar uit.
Dit stuk verscheen eerder in editie #177 van De Circulaire.
Afgelopen week had Arjen Lubach het in zijn Avondshow over overheidswebsites. Daar blijken er nogal wat van te zijn: bijna 1800. Veel van die sites dupliceren elkaar. Als je bijvoorbeeld iets wilt opzoeken over coronavaccinaties zijn er wel tien sites die je kan raadplegen. En ze verwijzen ook nog allemaal naar elkaar. En dat gaat alleen nog maar over corona. Er zijn ook talloze sites over het verduurzamen van je huis, beter omgaan met geld of gezonder eten. Met ‘handige’ tips als ‘doe eens meer groente in je bami’. Bedankt, vadertje overheid!
De hoeveelheid sites was niet wat me het meest opviel toen ik wat willekeurige sites uit die lijst bekeek. De Rijksoverheid is nou eenmaal een enorm orgaan met talloze afdelingen en campagnes. Het was vooral de zinloosheid van al die sites. Er zijn veel goed geproduceerde fimpjes, die niemand kijkt. Mooi geschoten foto’s die niemand ziet. En een kennis vertelde me dat al die sites een dure toegankelijkheidsaudit moeten ondergaan. Ik betwijfel dat iemand het merkt.
De toon van de teksten viel me ook op. Óf het lijkt geschreven te zijn voor een kind van vijf (zoals die bami-met-groenten-tip), óf de teksten lijken geschreven te zijn voor mensen die minstens hoogleraar in de rechten zijn. Om een voorbeeld te geven: de homepage van de Adviescommissie Gegevensverstrekking Weigerende Observandi (2 bezoekers per dag) legt zo uit wat ze doen:
De AGWO adviseert de officier van justitie over de bruikbaarheid van de verkregen behandelgegevens, bezien vanuit de strafzaak. De officier van justitie kan vervolgens een vordering indienen bij de penitentiaire kamer van het Gerechtshof Arnhem-Leeuwarden.
Op de hele site is alleen in een PDF die op een subpagina staat te lezen wat een ‘observandi’ is (een verdachte die een onderzoek naar een psychische stoornis weigert).
Ik betwijfel dat het veel zin heeft om de zoveelste site op te tuigen met tips hoe je van je schulden af kunt komen of gezonder kunt eten. Dat komt ook door twee interviews die ik de afgelopen twee weken luisterde.
Presentator en comedian Edson da Graça (die ondermeer het fantastische jeugdprogramma Gewoon bloot presenteerde) was te gast bij de podcast van Pepijn Schoneveld. Hij zat ooit diep in de schulden. Hij kwam eruit doordat een collega het doorhad en hem hielp. Gewoon door met hem door z’n administratie te gaan, instanties te bellen en uitstel van betaling aan te vragen. Waarom was hij ooit in die schulden gekomen en er niet zelf uitgekomen? Natuurlijk, omdat zijn omgeving hem daar nooit op had gewezen. Als je niet weet dat er regelingen zijn, dat je brieven kunt sturen naar instanties en gemeentes dan doe je dat niet. Zeker niet als je jezelf enorm schaamt voor het feit dat er stapels met incassobrieven liggen.
Dat je je niet kunt voorstellen dat iemand zoiets niet weet heeft te maken met privilege. Een onderwerp dat uitgebreid ter sprake in het marathoninterview met publicist Joris Luyendijk, die vorig jaar het boek De zeven vinkjes publiceerde. Een van zijn belangrijkste punten is dat privilege niet alleen maar gaat over huidskleur, of gender of seksuele voorkeur. Het gaat óók over sociale klasse. Een geadopteerd Koreaans meisje dat opgroeit in een gezin met twee witte universitair geschoolde ouders in Amsterdam-Zuid heeft meer kansen dan een witte heteroseksuele Poolse bouwvakker met alleen basisschool die gebrekkig Nederlands spreekt. Dat meisje zal de weg wel kunnen vinden dankzij haar ouders, voor die bouwvakker zijn de kansen een stuk kleiner.
De menselijke maat
Even terug naar die overheidswebsites. Bij zowel het interview met Da Graça als dat van Luyendijk ging het over hoe we kunnen zorgen voor meer inclusie. Of hoe een drama zoals het toeslagenschandaal voorkomen had kunnen worden. Ik denk dat ik weet wat in ieder geval níet werkt: de zoveelste website met open deuren optuigen.
Een veel betere oplossing is die waar Da Graça het over had: een mens van vlees en bloed die naast je zit en met je door je administratie gaat. Dat heb ik zelf ook zo ervaren, toen ik als vrijwilliger mensen hielp in het lokale buurthuis. Bij het aanschrijven van de gemeente om bijzondere bijstand te krijgen, of om een DigiD aan te vragen. Die mensen waren echt niet achterlijk, ze hadden gewoon géén idee hoe ze met een computer moeten omgaan en de ‘taal’ van de overheid spreken.
Maar ja, zo’n oplossing is als je er met een neoliberale bril naar kijkt veel te duur. Ook een reden waarom bijvoorbeeld banken hun klanten vertellen dat ze moeten internetbankieren, en de afgelopen tien jaar driekwart van hun filialen sloten.
Weer de zoveelste website optuigen met tips lijkt me dus vooral iets voor de bühne. Om de minister te laten zien dat er heus wel iets gebeurt. En een goede reden om een congres te organiseren met ‘gedurfde gesprekken’ en een gebakje te eten omdat de 1801-ste overheidswebsite is opgetuigd.
Hay Kranen (rechts) overhandigt zijn Twitterarchief per USB-stick aan Migiza Victoriashoop, hoofd collecties van het Stadsarchief Amsterdam. 📷 Mirjam Schaap
Donderdag 12 januari fietste ik naar De Bazel, het kolossale gebouw aan de Vijzelstraat waar sinds 2007 het Stadsarchief Amsterdam is gevestigd. In mijn binnenzak zat een USB-stick met een zipje van 195 megabyte: mijn Twitterarchief. Dat archief bevat alle tweets die ik heb verstuurd tussen 18 januari 2008 (de dag waarop ik mijn eerste tweet schreef) en 19 november 2022 (de dag dat ik het archief heb opgevraagd). Nog meer in dit archief: zo’n 21.000 tweets en 6.000 likes. Van een van de eerste tweets die ik ooit stuurde waarin ik boos was op de klantenservice van Epson tot een van de laatste waarin ik naar mijn Mastodon-profiel linkte.
In De Bazel had ik een afspraak met Migiza Victoriashoop, hoofd collecties, en Mirjam Schaap, adviseur verwerving en ontsluiting van digitale particuliere archieven. Ik had gereageerd op een bericht van Mirjam, die vroeg of er Amsterdammers waren die hun Twitterarchief wilde doneren. Dat wilde ik wel. Een paar dagen eerder had ik mijn archief gedownload. Daarna verwijderde ik al mijn tweets. Voor het hoe en waarom moeten we even terug in de tijd.
Een ander soort internet
Toen ik in 2008 mijn eerste tweet schreef was het internet een ander soort plek. Optimistischer, zeker onschuldiger maar wellicht ook naïever. Als ik naar de oudste tweets kijk is het een dagboek, met antwoorden op de vraag ‘wat ben je aan het doen’. Ik schreef niet met het idee dat er mogelijk een publiek meeleest dat je niet kent. Twitter was op dat moment nog echt een niche. Er was een overzicht van de actiefste Twitteraars in Nederland, en daar stond ik, als onbekende Nederlander, ook gewoon tussen. Veel van de mensen in die lijstjes kende ik ook wel, omdat ze actief waren in de technologie- en mediasector.
In 2008 werkte ik bij een techstartup die zich bezighield met set-top boxen (zoals die boxen van kabelaars als Ziggo). In 2009 begon als webontwikkelaar bij VPRO Digitaal. Typisch plekken waar je early adoptors zou tegenkomen van een dienst als Twitter. Misschien ook niet zo gek dus dat ik er vroeg bij was. Ik twitterde veel over vakrelevante zaken (nieuwe tools, conferenties, sites) maar ook andere dingen die ik tegenkwam. Grappige filmpjes, observaties en irritaties van het dagelijks leven, wat ik die avond at. Niet al te serieus dus.
In de loop der jaren veranderde Twitter sterk. Er kwamen steeds meer media en belangrijke personen op, en de toon veranderde van ‘de kroeg op de hoek’ naar ‘het gesprek van de dag’. Steeds vaker ging het over actuele onderwerpen, nieuws werd belangrijker, en mensen namen ook steeds vaker een standpunt in. Dat verkondigden ze dan, vaak in niet al te subtiele bewoordingen. Door het grotere publiek dat op het medium zat werd jezelf profileren en een harde mening hebben net zo belangrijk als gewoon een beetje schrijven wat in je opkwam.
Ik denk dat dit onbewust de reden is geweest dat ik in de afgelopen jaren een stuk minder ben gaan twitteren. Ik gebruikte het als plek om mijn eigen werk te promoten, en ik reageerde soms op tweets van bekenden. De gezelligheid van het oude Twitter is grotendeels vervangen door privé-groepen op andere apps zoals WhatsApp, Telegram en Signal. Wel jammer, want juist het feit dat je met wildvreemden in gesprek kon raken was de charme van het oude Twitter. Ik heb zelfs een keer een meetup gehad met een paar van die mensen, waarvan ik er één nog steeds wel eens zie. In 2011 kreeg ik een relatie met een vrouw (inmiddels is ze mijn echtgenote) waarin Twitter een belangrijke rol speelde.
Het einde en het archief
Het moment dat ik definitief besloot om (grotendeels) afscheid te nemen van Twitter was de overname van het platform door Elon Musk op 27 oktober 2022. Het werd duidelijk dat Musk de site wilde herscheppen. En dan volgens zijn eigen wereldbeeld met zijn eigen standpunten in plaats van een poging te wagen het neutraal en veilig te maken. Ik besloot toen om mijn archief te downloaden en alle tweets te verwijderen. Het is volledig onduidelijk wat er in de toekomst gaat gebeuren met Twitter en mijn data. Ik heb het dan liever in eigen hand dan te hopen dat Musk er geen rare dingen mee gaat doen.
Mijn account @hayify heb ik nog steeds. Ik tweet sporadisch, want het blijft ook voor mij een manier om mijn werk te promoten en op de hoogte te blijven. Maar grotendeels ben ik overgestapt op andere platforms. Korte berichten doe ik op Mastodon, en soms ook wel eens wat op Instagram of LinkedIn. En er is natuurlijk dit blog en mijn nieuwsbrief.
Het archief is op termijn beschikbaar via het stadsarchief. Mirjam en Migiza legden me uit dat dit nog wel even kan duren. Een Twitterarchief is weer heel wat anders dan een foto, een perkamenten rol of een boek. En dan zit je nog met de auteursrechten, want mijn archief bevat ook foto’s en data van anderen. Voorlopig zal het alleen beschikbaar zijn binnen de muren van het archief zelf, op aanvraag.
Maar dat is allemaal prima. Het idee alleen al dat iemand over honderd jaar mijn boze tweet over de klantenservice van Epson kan lezen vind ik fantastisch. En als u dit leest over 100 (of iets minder) jaar: u vindt mijn archief onder toegangsnummer 31451 en aanwinstnummer 2023-9.
Lotte Belice doneerde ook haar Twitterarchief aan het stadsarchief en schreef daar dit over.
Mijn vrouw en ik zijn gek zijn op koken. Een van onze aanwinsten in onze keuken is ons kruidenkastje. Naast het gasfornuis hebben we een smal kastje met 5 laatjes vol kruiden. In totaal 55 doosjes. Allemaal netjes gelabeld met een labelprinter. Kurkuma. Komijnpoeder. Nigellazaad. Oregano. Noem maar op.
Je kunt dus wel zeggen dat ik hou van organiseren. Ik heb altijd een kinderlijk genoegen gehad om dingen in de juiste mapjes en laatjes te doen en er stickertjes op te plakken met de juiste termen. Of het nou kruiden zijn, of LP’s, of kattengifjes.
In mijn werkzame leven probeer ik dingen ook goed te organiseren en informatie vast te leggen. Ik maak aantekeningen, plan afspraken en maak takenlijstjes. Zoals iedereen dat doet. De modieuze term voor zo’n ‘systeem’ van organisatiedingetjes is een Personal Knowledge System (PKM). Sommigen gebruiken schriftjes en kladblokken met aantekeningen en taken. Anderen sturen zichzelf e-mails en gebruik hun inbox als PKM. En anderen maken er een sport van en proberen hun leven zo goed mogelijk te organiseren met een verzameling aan minutieus goed afgestelde gereedschappen en handigheidjes (guilty as charged).
Een PKM bestaat dus uit meerdere onderdelen, met als hart een manier om informatie en aantekeningen te maken en organiseren. Maar mijn notitiesysteem was al een tijdje toe aan een upgrade. Ik had papieren schriftjes, maar het liefst maak ik aantekeningen digitaal. Ik had sinds 2013 zo’n 360 aantekeningen gemaakt in NvAlt, een oud en stoffig pakket dat al jaren geen updates meer had gehad en overduidelijk toe was aan vervanging.
Eind 2021 nam ik de tijd om op zoek te gaan naar alternatieven. Er waren nogal wat opties. Zo is er Evernote, Apple Notes, Google Keep, OneNote, Simplenote, Notion, Roam Research en nog vele andere.
Maar die hadden allemaal niet wat NvAlt wél had en waarom ik er zo lang gebruik van maakte. In NvAlt leven je notities op je eigen computer in plaats van ergens in een cloud. Elke notitie is een tekstbestandje in een folder, en die folder synchroniseer je met je andere apparaten. Jouw data blijft dus jouw data, en zit niet vast in een online pakket.
Sinds 2013 waren er gelukkig wel wat opties bijgekomen die volgens dat principe werkten. De drie populairste zijn Obsidian, Joplin en Logseq. Die heb ik alle drie getest. Van de drie vond ik Obsidian duidelijk het beste. Joplin en Logseq zijn dan wel open source (Obsidian is grotendeels gratis, maar niet open source) maar ik vond Obsidian een stuk stabieler en vriendelijker in het gebruik.
Switchen naar Obsidian
Goed, overstappen naar Obsidian dus. Maar wat maakt Obsidian anders dan alle andere notitieapps? Obsidian lijkt op een soort persoonlijke Wikipedia. Het is even wennen als je het voor het eerst gebruikt en een leeg scherm voor je krijgt. De app is vooral gericht op het schrijven van notities en manieren om die met elkaar te linken, alhoewel er ook (beperkte) mogelijkheden zijn om media te verwerken.
Het mapje met notities heet in Obsidian-termen een vault. Je notities zijn standaard tekstbestanden in het Markdown-formaat. Markdown is een soort HTML-achtige taal om je tekst mee op te maken. Om bijvoorbeeld iets vet te maken maak je gebruik van *sterretjes*. Of om een link te maken naar een ander artikel gebruik je [[dubbele blokhaken]] (net zoals op Wikipedia).
Dat klinkt vrij nerderig, maar de editor werkt prettig genoeg om het snel door te hebben en er is uitstekende documentatie. Het werken in die tekstbestanden heeft een groot voordeel: de bestanden blijven altijd van jou, en blijven leesbaar. Ze staan op je eigen computer, en je bent dus niet gebonden aan een maandelijks abonnement van een dienst die er zomaar mee kan ophouden (zoals het voormalige platform waar deze nieuwsbrief op draaide) of je maandbedrag kan verhogen. Zelfs als Obsidian niet meer werkt kun je die tekstbestanden nog steeds bekijken in elke willekeurige teksteditor.
Obsidian is grotendeels gratis. Officieel moet je $50 per jaar betalen als je het commercieel gebruikt, maar dat wordt niet gecontroleerd. Daarnaast kun je betalen om je bestanden te syncen met andere computers zodat je ze daar ook kan gebruiken ($8 per maand) of je notities online te publiceren ($16 per maand). Je kan beide echter ook voor elkaar krijgen zonder te betalen. Syncen kan ook met bijvoorbeeld Dropbox of iCloud en ook voor publicatie zijn opties.
Een ander ding wat Obsidian zo geweldig maakt is de enorme community die rond het pakket zit. Er is een Discord, en er zijn actieve fora en eindeloze YouTube-video’s waarin mensen uitleggen hoe alles werkt (deze video van 13 minuten is heel geschikt voor beginners). Naast de ingebouwde functionaliteit kun je Obsidian ook uitbreiden met plugins. Daar zijn er op het moment van schrijven een stuk of 800 van. Die plugins laten je bijvoorbeeld makkelijker tabellen en diagrammen maken, of een kalender toevoegen.
Verdrinken in mogelijkheden
Een pakket waar dus alles in kan, en waarin je helemaal vrij bent om alles in te richten. Geweldig, maar ook gelijk het grootste nadeel. Want waar begin je? Op YouTube zijn talloze filmpjes te zien van mensen die hun Personal Knowledge System binnen Obsidian demonstreren, of je introduceren in de wondere wereld van het Zettelkasten-systeem. Dat maakte mij in het begin een beetje moedeloos, want je gaat aan jezelf twijfelen of jouw manier van inrichten wel ‘de juiste’ is.
Het duurde even voor ik doorhad dat er niet één manier is om dat te doen. Iedereen doet het weer anders, en het is aan jou om je eigen systeem in te richten. Het handigste is dus om gewoon maar te beginnen en later daar een systeem mee vorm te geven.
Na een jaar Obsidian heb ik bijna 500 notities en een systeem. Dat komt er grofweg op neer dat ik notities verdeel in vier types:
Projecten. Dingen waar ik aan werk. “haykranen.nl” is bijvoorbeeld een project. Maar ook “Fiets” is een project, waarin ik bijhoud welke moersleutel ik ook alweer nodig heb als ik het zadel wil verstellen.
Bronnen. Compleet complete gedownloade webpagina’s (via deze handige browserplugin) of samenvattingen van boeken en artikelen die ik heb gelezen.
Onderwerpen. Bijvoorbeeld “AI”, “Immersief theater” of “Design”, maar ook “Geveltuintjes” en “Rommelmarkt”. Hierin plaats ik ook bookmarks en algemene aantekeningen.
Notities. Alles wat niet in de bovenstaande types past, zoals aantekeningen van vergaderingen en conferenties.
Als je dan zo’n vault hebt gemaakt kun je ook een graaf maken van al je notities. Hoeveel zin zo’n graaf heeft weet ik eigenlijk niet, behalve dat het er cool uitziet:
Na een jaar te werken in Obsidian kan ik eigenlijk niet meer zonder. Dingen terugvinden, aantekeningen maken, nieuwe connecties tussen onderwerpen vinden, het werkt allemaal heel fijn. Nu nog een app om een extra dag in de week te toveren zodat ik die 360 oude aantekeningen uit NvAlt kan doorlezen en verwerken.
Dit artikel verscheen eerder in editie #174 van De Circulaire.

















{kind=link}