Het is een mooie traditie. Al sinds 2003(!) maak ik elk jaar trouw mijn lijstje met de beste muziekalbums van het afgelopen jaar. Toen ik begon bestond er nog geen Spotify en moest ik de muziek allemaal nog torrenten van de Piratebay kopen op CD’s. Ik luister steeds vaker losse nummers, maar het blijft toch een leuk idee om een ‘beste albums van het jaar’ lijstje te maken.
De albums in de top 10 linken naar Spotify en hebben een korte beschrijving. De volgorde na #10 is sowieso wat arbitrair.
Porridge Radio – Waterslide, Diving Board, Ladder To The Sky
Julia Jacklin – Pre Pleasure
De beste nummers van 2022
📷 Vevo / Columbia
Ik heb een Spotify-playlist gemaakt met mijn 30 favoriete nummers van 2022. Van elke plaat die je hierboven ziet staan staat er meestal ook wel een nummer in dit lijstje.
Liedje van het jaar? Ik twijfel tussen Runner van Alex G (tevens dus beste plaat van het jaar) en As It Was van Harry Styles. De clip van die laatste is in ieder geval fantastisch! Fun fact: dat gekke witte object waar Harry zich op uitkleed is het voormalige pinguïnverblijf van de London Zoo en tevens een rijksmonument.
De optredens van 2022
📷 HK
We mochten weer! In 2021 zag ik nul optredens, dit jaar was dat een stuk beter. Het beste concert was met vlag en wimpel Big Thief in TivoliVredenburg. Ik geloof niet dat ik ooit zo’n goede band heb gezien. Zangeres Adrianne Lenker stond helemaal rechts op het podium terwijl drummer James Krivchenia juist centraal zat. De volgende dag ging ik op vakantie, nog helemaal aan het nagenietend van een legendarisch optreden.
We zitten middenin een AI-revolutie. Het afgelopen jaar is er zo ontzettend veel gebeurd op het gebied van AI dat het lastig is om een beetje bij te blijven. Ik doe dat zelf door veel te lezen maar vooral door veel te spelen met de techniek. Om een revolutie te snappen moet je weten hoe dingen werken. In dit artikel wil ik je meenemen in een paar van de tools waar ik zelf de laatste tijd mee heb gespeeld.
Stable Diffusion
Stable Diffusion is één van de belangrijkste text to image-pakketten, samen met Midjourney en DALL-E. Waar het zich onderscheidt van die andere twee is dat het een stuk opener is. De code die je gebruikt om de plaatjes te genereren is volledig open source, het model (dat nodig is om plaatjes te genereren) mag je downloaden en verspreiden. Dat betekent dus dat je de code én het model kunt downloaden op je eigen computer en plaatjes kunt genereren zonder een maandelijks abonnement te nemen (Midjourney) of credits te kopen (DALL-E). Daarnaast zorgt dat open model ervoor dat andere mensen software kunnen bouwen op basis van Stable Diffusion.
Een voorbeeld is Diffusionbee. Dat is (ook weer) een open source-pakket (momenteel alleen Mac) dat een handige interface biedt die vergelijkbaar is met die van DALL-E en Midjourney.
Stable Diffusion en Diffusionbee draaien dus op je eigen computer. Dat betekent dat als je laptop wat ouder is, of minder krachtig, het genereren van plaatjes minder vlot gaat. Op mijn eigen machine, een Macbook Air met M1 processor en 16 GB geheugen, is Diffusionbee / Stable Diffusion zeker langzamer dan DALL-E of Midjourney. Een plaatje genereren duurt ongeveer een halve minuut, bij de cloud-gebaseerde concurrenten is dat vaak een paar secondes.
Maar de ontwikkelingen gaan snel. Toen ik twee maanden geleden een oudere versie uitprobeerde duurde dat genereren nog 3 tot 4 minuten per plaatje. Apple heeft inmiddels nét zelf een fork uitgebracht die efficiënter gebruik maakt van diens hardware. De genereer-tijden zullen dus ongetwijfeld de komende maanden en jaren nog fors naar beneden gaan als de code wordt doorontwikkeld en machines sneller worden.
Wat kun je zoal met Stable Diffusion? Diffusionbee biedt vier opties die vergelijkbaar zijn met de concurrentie. Ik zal ze hier illustreren aan de hand van een foto van mijn favoriete knuffelaap (en de mascotte van mijn nieuwsbrief): Barrie.
Barrie, in zijn niet-door-AI-gegenereerde staat
Bij text to image tik je een stukje (Engelstalige) tekst in (de zogenaamde prompt) en komt er een plaatje uit. Bij Stable Diffusion kun je ook nog een hoop instellen. Bijvoorbeeld hoeveel plaatjes je wilt maken (vier is de standaard bij DALL-E en ik vind het zelf ook een goed aantal). Je kunt de resolutie instellen en hoe strikt de AI je prompt moet ‘volgen’. Ook kun je een ‘negative prompt’ instellen. Dit kan helpen om je afbeelding te verfijnen. Als je merkt dat de apen op je plaatjes er heel harig uitzien kun je ‘hairy’ invullen als negative prompt en zal de AI minder harige apen fantaseren.
Een ongemakkelijk kijkend Boliviaans doodskopaapje volgens Stable Diffusion
Zo’n prompt schrijven is nog een hele kunst. Prompt engineer is vast binnenkort een functie. Een goede manier om daar wat meer over te leren is door te kijken naar de werken op sites als lexica.art of arthub.ai, waar altijd de prompt bij staat. Deze PDF is ook nuttig. Ook al is het geschreven voor DALL-E, de principes zijn van toepassing op alle algoritmes.
De andere kant op, dus van plaatje naar tekst, kan niet met Stable Diffusion. Maar er is natuurlijk wel weer een andere tool voor zoals de CLIP interrogator. De originele foto van Barrie leidde bijvoorbeeld tot deze prompt:
a close up of a stuffed animal on a table, a character portrait, inspired by Thomas Stothard, marmoset toolbag, black centered pupil, sheep wool, yelow, selfie photo, worried, mottled coloring, matteo salvini, twitch emote, connectedness, sheep, banana, etsy
Een beschrijving die op z’n minst verrassend is. Een marmoset is een aap, maar een ‘toolbag’? En hoe Matteo Salvini (de leider van de Italiaanse populistische Lega Nord) en de 18-de eeuwse Britse schilder Thomas Stothard in de beschrijving terechtkomen is een raadsel. Hoe dan ook, als je deze beschrijving weer in Stable Diffusion gooit krijg je ook weer interessante dingen.
Text to image is de basismodus, maar de andere modi in Diffusionbee zijn minstens zo interessant. Met inpainting kun je delen van een afbeelding weggummen en weer combineren met een prompt om die zo in te vullen. Een soort magische Photoshop. Het is soms een beetje zoeken met deze modus, maar het kan ook een manier zijn om te itereren en je afbeelding stukje bij beetje uit te breiden of te verbeteren. Bij de volgende plaatjes gumde ik bijvoorbeeld Barrie’s ogen en mond weg en gaf ik als prompt ‘knuffelaap met zonnebril / sigaret’
Barrie met een zonnebril en een sigaret
Outpainting lijkt op inpainting maar is weer net anders: in plaats van dat je in de afbeelding dingen weggumt fantaseert de AI de wereld buiten het plaatje. Bij deze plaatjes hield ik dus alleen Barrie’s gezicht over en gaf ik als prompt ‘knuffelaap met een hoed’.
Je bent hier niet beperkt tot het vierkante canvas. Je kan het canvas ook naar alle kanten uitbreiden.
En je kan hier ook weer delen weggummen. Als je bijvoorbeeld alleen Barries ogen behoudt en de rest invult krijg je ook weer verrassende resultaten.
Tenslotte is er de optie image to image. Wat mij betreft de meest interessante. Hiermee genereer je, net zoals bij text to image, een plaatje op basis van een prompt. Maar het verschil is dat je een afbeelding kunt gebruiken als input om de ‘stijl’ van de afbeelding aan te wijzen. Een soort combinatie van een tekst en een afbeeldings-prompt. Je kunt aangeven hoeveel de nieuwe afbeelding op de oude moet lijken.
Je kunt de nieuwe omschrijving zo gek maken als je zelf wilt. Barrie kan een kat worden.
Of je kunt de afbeelding genereren in de stijl van je favoriete kunstenaar.
Barrie in de stijl van (met de klok mee vanaf boven links): Georgia O’Keeffe, Picasso, Vermeer en Rembrandt
Die “variaties in de stijl van een kunstenaar” roepen een hoop vragen op. Want van wie zijn deze plaatjes eigenlijk? Van de makers van de software? Van de persoon die de prompt heeft geschreven? Of van de talloze makers van de afbeeldingen waarop de neurale netwerken zijn getraind?
En dan hebben we het alleen nog maar over afbeeldingen! Een van de meest opzienbarende nieuwe toepassingen van AI is juist op het gebied van tekst. Minder dan twee weken geleden kwam ChatGPT uit, een chat-variant van het eerder gelanceerde GPT-3. ChatGPT is een chatbot, maar eentje die een stuk intelligenter is dan die je bijvoorbeeld vindt op de klantenservice-pagina van de gemiddelde webwinkel. Het is lastig om duidelijk te maken wat ChatGPT precies is zonder het zelf te proberen. Zie het als een soort van veel slimmere en natuurlijkere variant van Google. Voorlopig is ChatGPT trouwens gratis, in tegenstelling tot DALL-E.
Je kunt ChatGPT vragen stellen (ook in het Nederlands).
Maar de manier hoe je die vragen stelt en ook hoe ze beantwoord mogen worden is geheel aan jou.
Je kan ChatGPT zelfs iets proberen te leren, zoals een taal. En je kan ChatGPT ook je eigen teksten laten herschrijven.
Wat er ook allemaal nog gaat gebeuren, het is een feit dat we aan het begin staan van een enorme verandering in hoe we met digitale media creëren. Zoals met elke technologische innovatie betekent het niet dat mensen van de ene op de andere dag overbodig worden. Maar dat hun werk zal veranderen staat vast. Een beetje kennis en kunde van deze technologieën kan dan ook geen kwaad.
En als je daar geen zin in hebt kun je altijd nog je e-mails naar je baas genereren. Of dit blog lezen.
Dit artikel verscheen eerder in editie #172 van De Circulaire.
Eind augustus was ik bij het Paradisodebat. Dat is het jaarlijkse debat tussen de politiek en de cultuursector, georganiseerd door belangenorganisatie Kunsten ‘92. Acht mensen uit de sector hadden nette vragen geformuleerd, die ze stelden aan vijf kamerleden met cultuur in de portefeuille. De conclusie: de toekomst voor de kunsten was hoopvol.
Helemaal aan het einde vroeg de moderator of de zaal na het debat ook hoopvol was. Kunstenaar Katinka Simonse (Tinkebell) reageerde verontwaardigd: “dit is een blamage”, schreeuwde ze. “Dit is een slaapverwekkend debat vol met cliché’s”. Er werd wat gemurmeld en ze werd afgewimpeld met “kom maar bij de borrel vertellen hoe het dan had gemoeten”. Tijdens de uitreiking van een koninklijke onderscheiding door de staatsecretaris Cultuur en Media aan de vorige voorzitter van Kunsten ’92 liep ze boos weg.
Ik begreep Tinkebell wel. Want het wás ook een slaapverwekkend debat vol cliché’s. De wereld staat in brand. De politici zeiden dat het “zo goed was dat we hier ondanks alle politieke verschillen zitten” terwijl ze benadrukten hoezeer ze het met elkaar eens waren. Ik kan me geen recent politiek debat herinneren waarbij de deelnemers het mordicus met elkaar óneens waren. Stel je voor! Een debat dat ongezellig is en waar deelnemers zich misschien soms wat ongemakkelijk voelen!
Het werd maar op één moment een beetje spannend. Eerder zeiden de politici hoe belangrijk het was dat de cultuursector rust krijgt. Ze hadden het dan vooral over de (vaak grotere) BIS-instellingen, die steun van de overheid krijgen. De Amsterdamse wethouder van cultuur Touria Meliani stelde de logische vraag: krijgen de gemeentes dan ook rust? Krijgen ze financiële steun voor het Gemeentefonds door het Rijk zodat ze hun eigen instellingen kunnen ondersteunen? Die vraag werd weggewuifd. Kamerlid Pim van Strien (VVD) vond dat een ongepaste vraag op een middag waar zo fijn werd gepraat over “de toekomst en wat ons verbindt”.
Inderdaad, slaapverwekkend en clichématig. Gezellig keuvelen, elkaar schouderklopjes en complimentjes geven dat we het allemaal zo heerlijk eens zijn. Alsof daarmee de verdeeldheid in de maatschappij, de klimaatcrisis, de vluchtelingencrisis, de stikstofcrisis en alle andere crisissen worden opgelost.
Een week later zat ik bij een interview met Maria Alyokhina, mede-oprichter van de Russische punkband Pussy Riot. Sinds april dit jaar is ze uit Rusland gevlucht, omdat ze alleen al voor het gebruik van het woord “oorlog” in plaats van “speciale militaire operatie” vijf jaar cel kan krijgen. Hier zit iemand die haar land is ontvlucht, omdat ze het niét eens is met hoe de dingen gaan. Om te laten zien hoe dicht we bij de oorlog in Oekraïne zitten spuit ze nu graffiti bij plaatsnaamborden waar ze langskomt, die het aantal kilometers tot de Oekraïense grens aangeven.
Iemand uit het publiek vroeg hoeveel zin dat eigenlijk heeft: dat actievoeren. Want het is ontzettend deprimerend. Had ze niet de neiging zichzelf van een brug af te gooien? Haar precieze reactie weet ik niet meer, maar wel wat ze daarna zei: je weet nooit van tevoren hoeveel impact een actie, hoe klein dan ook, kan hebben. Als niemand begint gebeurt er niks. Alyokhina kreeg ook de vraag of kunst a-politiek kan zijn. Nee, zei ze: “niet politiek zijn is namelijk óók een politiek statement”.
Dát is volgens mij wat Tinkebell bedoelde toen ze riep dat het Paradisodebat een blamage was. Scherpe politieke statements werden vakkundig vermeden. Het de hele tijd met elkaar eens zijn en benadrukken wat ons allemaal verbindt is óók een statement. Én een statement dat geen recht doet aan de huidige staat van de wereld. De helft van de Nederlanders heeft volgens recent onderzoek van het Sociaal en Cultureel Planbureau (SCP) geen of weinig vertrouwen meer in de politiek. Dát is een enorm probleem waar we een oplossing voor moeten vinden.
Die oplossing lijkt me eigenlijk vrij simpel: eerlijk zijn, mensen serieus nemen én duidelijke keuzes maken. Het gebrek daaraan is de reden dat al die vlaggen in het land omgekeerd hangen. Want heeft het kabinet ooit écht eerlijk en duidelijk uitgelegd waarom die stikstofmaatregelen worden doorgevoerd behalve “het is belangrijk en we kunnen niet anders”? Dat is geen eerlijkheid, maar onvermogen om te kunnen uitleggen hoe dingen werken. De persoon die werd aangesteld als “onafhankelijk bemiddelaar” bleek dezelfde te zijn als die eerder het rapport heeft geschreven waarop die maatregelen gebaseerd zijn. Natuurlijk hebben mensen dan het gevoel dat ze niet serieus worden genomen. Zou er niet veel meer respect zijn voor politici als ze duidelijke keuzes zouden maken, die fatsoenlijk uitleggen en niet vervallen in uitgekauwde cliché’s als “we betreuren het ontstane beeld”?
Die simpele oplossing is natuurlijk niet makkelijk. Niet iedereen kan vluchtelingen opvangen, zonnepanelen op het dak leggen of de politiek ingaan. Maar er zijn, wat Maria Alyokhina ook zei, duizend dingen die je wél kan doen. Daar kun je mee beginnen.
Er was nóg een moment bij het Paradisodebat dat bijbleef naast de boosheid van Tinkebell. Spoken word kunstenaar en schrijver Babs Gons trad op met een ode aan het doorzettingsvermogen van de creatieveling: doe het toch maar. Het blijven doen, ook als je denkt dat niemand op jouw ideeën of werk zit te wachten. Zouden we niet moeten beginnen met die vier woorden van Babs Gons?
Bij mij heeft het in ieder geval wat los gemaakt. Wat dat precies betekent weet ik nog niet, alleen dat ik me nog meer, ook professioneel, zal inzetten voor die drie waardes die ik hierboven heb genoemd: eerlijk zijn, mensen serieus nemen en duidelijke keuzes maken.
In 2011 zou het er zijn geweest een Nationaal Historisch Museum. Het zou een overzicht bieden van de Nederlandse geschiedenis. Maar het kwam er niet van. Het plan bleek te duur. En er moest bezuinigd worden op de culturele sector in het eerste kabinet Rutte (met de PVV). Meer dan een tijdelijk onderkomen in de Amsterdamse Zuiderkerk is het nooit geworden.
In het coalitieakkoord van het huidige kabinet Rutte-IV staat iets interessants: het voornemen om tóch weer een poging te wagen.
Maar is zo’n museum eigenlijk wel een goed idee? In een opiniestuk in het NRC van woensdag 1 juni betogen een vijftal mannen, waaronder historicus en schrijver Geert Mak, van niet. Zij krijgen het idee dat het hier vooral gaat om het kweken van nationaal bewustzijn ter compensatie van slecht geschiedenisonderwijs. Dat zou moeilijk gaan met een dergelijk museum.
De vijf heren stellen iets anders voor: een digitaal nationaal museum. We lezen:
Dat [museum] is: digitale toegang tot alle denkbare historische bronnen, in tekst, beeld en geluid. (…) Er valt nog een wereld te winnen om verschillende doelgroepen, afhankelijk van hun voorkennis en belangstelling, te bereiken en soepel te laten navigeren. Dit zijn oplosbare problemen, die minder kosten dan een in stenen gegoten museumgebouw.
Als digitale experts hebben wij tientallen jaren ervaring met het bouwen van digitale producten voor de erfgoedsector. Daarom weten we wat dat digitale museum van Mak en co is: een luchtkasteel.
Misvattingen
De auteurs stellen een ‘digitaal museum’ voor in de vorm van een website. Maar een visie van wat dat precies zou behelzen ontbreekt. We lezen een vaag idee van iets wat al bestaat of niet kan bestaan. Dat uit zich in een reeks misvattingen over digitale media.
Het begint met het uitgekauwde cliché dat een website „minder [zal] kosten dan een in stenen gegoten museumgebouw”. Behalve een hoop ronkende servers heeft een website inderdaad geen fysieke vorm. Maar is het daarom goedkoper? Dat is te betwijfelen. Het bouwen, onderhouden en vullen van een site kost geld. Veel geld. Digitale experts zijn niet goedkoop. Dat ict’ers rondrijden in Tesla’s, komt doordat ze een flinke uurprijs vragen.
De ambitie is ook groot: „digitale toegang tot alle denkbare historische bronnen, in tekst, beeld en geluid”. Wat moeten we ons daar bij voorstellen? Google? Daar werken 140.000 mensen. Rutte IV heeft ongetwijfeld niet de ambitie om dat na te gaan bouwen met belastinggeld.
En zitten mensen te wachten op een site die toegang geeft tot ‘alles’? Onze ervaring is dat mensen iets simpels willen, niet iets waar ze verzuipen in informatie. En zelfs ‘iets simpels’ is helemaal niet makkelijk. Een site als booking.com lijkt misschien simpel, maar er werken bijna twintigduizend mensen. Het is minstens zo lastig „alle denkbare historische bronnen” in een goede digitale vorm te gieten.
Compacte selectie
De auteurs noemen de website van de Canon van Nederland als voorbeeld. Maar vinden die ook „te weinig bieden” en „statisch”. We hebben de afgelopen jaren onderzoek gedaan naar het gebruik van digitaal erfgoed binnen het onderwijs. En wat blijkt? Leraren zijn maar wat blij zijn met die mooie, behapbare selectie van vijftig canonvensters in de Canon van Nederland. Leraren zijn al druk genoeg, die hebben helemaal geen tijd om zelf miljoenen bronnen te doorzoeken. Juist de compacte selectie in tijdvakken en vensters helpt hen. Daarbij sluit de canon aan op het curriculum en lesmethoden. En hoezo statisch? In 2020 werd de canon vernieuwd met onder meer Anton de Kom (over het slavernij- en koloniale verleden) en Marga Klompé (eerste vrouwelijke minister).
Mak en co schrijven dat het gedigitaliseerde omroeparchief van Beeld en Geluid ligt te „verstoffen” omdat het niet digitaal toegankelijk is. Helaas maakt het auteursrecht het buitensporig complex en kostbaar om archieven online te zetten. Een groot deel van het archief is overigens voor het onderwijs wel degelijk online te raadplegen.
Ook andere erfgoedinstellingen zouden hun collecties als „los zand” digitaal beschikbaar stellen. Hebben de auteurs recent wel eens gekeken op een website van een willekeurig museum of archief? De toegang tot digitaal gepresenteerd erfgoed is enorm verbeterd de afgelopen tien jaar. Er wordt via samenwerkingsverbanden zoals het Netwerk Digitaal Erfgoed gewerkt aan portalen, standaarden en linked data-uitwisseling. En kijk eens op een site als Delpher, waar het enorme krantenarchief van de Koninklijke Bibliotheek op te vinden is. Daarnaast zijn er talloze initiatieven zoals Europeana en Netwerk Oorlogsbronnen die op grote schaal historische bronnen verzamelen en aan elkaar koppelen.
De schrijvers zeggen dat van de gedigitaliseerde collecties van musea „wel degelijk aansprekende, verdiepende en ‘geanimeerde’ producties te maken” zijn. Want die laten zich „op verschillende manieren toegankelijk maken, via tijdlijnen, topografische kaarten en uiteenlopende thema’s”. Inderdaad. Zoals de door de auteurs weggewuifde Canon van Nederland met tijdlijnen, kaarten en thema’s.
Gebrek aan digitale kennis
Als we naar de auteurs van het stuk kijk valt ons nog iets op. Dit zijn vijf mannen: vier historici en één journalist. De jongste van het stel is 62, de oudste 82.
Missen we daar iets? Inderdaad: experts op het gebied van digitale media. Omdat iedereen de hele dag online is denken mensen er ook verstand van te hebben. Helaas is het net zoals met elk ander vak: je hebt er kennis en kunde voor nodig om het beste eruit te halen. Het is makkelijk om vanaf de zijlijn te roepen dat je wel weet hoe het moet als je er zelf geen verstand van hebt.
Fysiek én digitaal
Echte digitale innovatie ontstaat als de sector de handen ineenslaat en er meer expertise in huis wordt gehaald. Op het gebied van user experience, mediaproductie, gebruikersonderzoek, digitale strategie en projectmanagement in het algemeen. Het is een enorme misser om te beweren dat digitaal alles bij elkaar harken de oplossing is, want goedkoper dan stenen. Dat moet niet het argument zijn. De vraag is: wat is je doel? En: hoe kan je dat bereiken? Onze ervaring is dat dit voortkomt uit de combinatie van fysieke en digitale ervaringen, en professionals die geweldige producten, ervaringen en media maken die elkaar versterken.
De kracht van een Nationaal Historisch Museum zit in ontmoeting, discussie en confrontatie. Fysiek én digitaal. Elkaar versterkend. Want het zijn geen losstaande werelden.
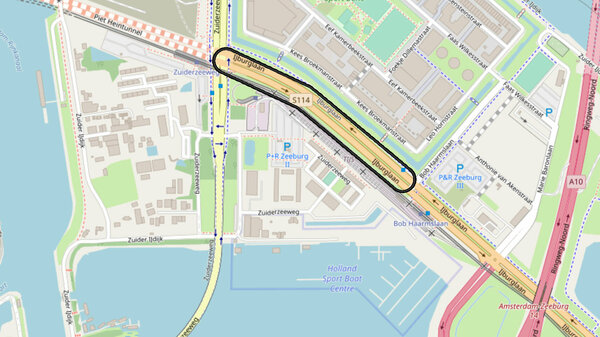
De IJburglaan is een belangrijke verkeersader in Amsterdam. Vanaf afslag 14 op de ringweg A10 loopt de laan twee kanten op. Oostelijk over de lengte van de wijk IJburg, westelijk richting het centrum.
Over dat laatste deel wil ik het hebben. Het is een belangrijke doorvoerroute. De IJburglaan gaat naar de Piet Heintunnel, die de laan verbindt met de Piet Heinkade in het centrum.
De tunnel is tot eind september dicht voor onderhoud. En rondom de laan zijn veel (bouw)werkzaamheden. Routes lopen niet zoals ze normaal lopen. En daarom staan er borden langs de IJburglaan. Heel veel borden.
Nee, er staan er echt heel veel.
Héél veel.
De afstand vanaf de afslag op de A10 tot het kruispunt met de Zuiderzeeweg (waar de afgesloten Piet Heintunnel begint) is net iets meer dan een kilometer. Hoe je precies ‘een bord’ telt is natuurlijk subjectief, maar op die ene kilometer tel ik er zelf rond de 70.
De grootste concentratie borden zit op de laatste 500 meter, net voor de kruising. Als ik alleen de borden tel die een omleiding of een andere tijdelijke situatie aankondigen kom ik uit op 21 stuks. Over dat stukje rijd je ongeveer 24 seconden. Gemiddeld heb je dus net iets meer dan een seconde om een bord te lezen. En dan moet je ook nog op de weg letten!
Zijn al die borden echt zo belangrijk dat ze er állemaal moeten staan? Nee. Er zijn borden die niet meer van toepassing zijn. Maar in plaats van dat ze worden weggehaald is er tape overheen geplakt.
Maar een stuk ducttape over een bord plakken betekent niet dat je dat bord niet ziet. Je ziet het wel degelijk, maar denkt vervolgens: oh ja, dit moet ik eigenlijk niet bekijken, want het klopt niet meer.
Dan zijn er de borden die aangeven dat de Piet Heintunnel is afgesloten (dus de route rechtdoor) en dat je naar links of rechts moet.
Dezelfde boodschap, maar dan op vier verschillende manieren uitgebeeld (het middelste bord heeft pijlen op zowel een fysiek bord als op een matrixscherm).
En tenslotte is er de boodschap dat je voor de route naar het centrum het bord met de letter ‘A’ moet volgen.
Opvallend is hier dat er veel melding wordt gemaakt van de omleiding (en dat je ‘A’ moet volgen) maar dat er op de hele route maar twee borden staan met de ‘A’ en dat van die twee er één ook nog de verkeerde kant op wijst.
Op de IJburglaan staan dus 21 borden die heel omslachtig iets proberen uit te leggen wat helemaal niet zo ingewikkeld is:
De Piet Heintunnel is dicht.
Je kunt nog wel naar links of naar rechts.
Links is het centrum.
Het zou helpen als ze alle borden die met ducttape zijn afgeplakt zouden weghalen. En dan nog een keer de helft weghalen. En de borden die je dan laat staan dezelfde iconen geven (dus niet pijlen op vier manieren). Maar gaat dat gebeuren? Ik betwijfel het. Voorlopig komen er vooral borden bij.
Je kunt je afvragen: hoe ontstaat zo’n situatie?
Ik heb geen studie gedaan naar wie al die borden op de laan heeft neergezet, maar ik heb wel een vermoeden. Het viel de Amerikaanse computerprogrammeur Melvin Conway ooit op dat organisaties systemen ontwerpen die hun communicatiestructuur reflecteren. Later werd dat de wet van Conway genoemd. Als je dat eenmaal weet zie je het overal.
De gemeente Amsterdam heeft 14.000 medewerkers. Het lijkt me dus geen gekke aanname dat er heel veel losse afdelingen zijn die allemaal die borden hebben geplaatst. Maar dat er niemand verantwoordelijk was voor het totaalplaatje.
Oftewel: niemand bekeek de complete customer journey van de automobilist die vanaf de A10 richting het centrum wil en niet zo goed weet hoe dat moet als de Piet Heintunnel dicht is.
Jaren geleden was ik in het Nederlands Openluchtmuseum in Arnhem. Ik liep in een plaggenhut en daar stond opeens een vrouw in traditionele klederdracht. “Ik ben een Drentse boerin, en dit is mijn huis.” zei ze. Het idee was dat je haar vragen kon stellen en dat ze die dan in character zou beantwoorden. Ik voelde me vooral opgelaten en ongemakkelijk en liep snel verder.
Dat was mijn eerste ervaring met iets wat men tegenwoordig immersief of onderdompeltheater noemt. In plaats van dat je in een zaal zit en kijkt naar een voorstelling op een podium, loop je rond door een ruimte. En je mag alle objecten aanraken en bekijken. Dat is zelfs vaak een cruciaal onderdeel van het verhaal. Je mag dus ook praten met de acteurs / karakters die rondlopen. Eigenlijk een beetje zoals we dat gewend zijn van pretparken zoals de Efteling. Alleen dan niet voor kinderen, maar voor volwassenen.
Ik vind het een fascinerend concept. In het beste geval combineer je de mogelijkheden van moderne open world videogames als GTA of Minecraft met de ervaring van traditioneel fysiek theater. Maar het is nog een relatief ongebruikelijke vorm, zeker in Nederland.
Het beste voorbeeld dat ik ken voor reguliere theaters zijn de projecten van het Belgische collectief Ontroerend Goed. In de voorstelling £¥€$ (‘lies’) word je met een groep medebezoekers aan een casinotafel gezet met een acteur en moet je actief beslissingen maken over het grote geld. Zo leer je hoe de kredietcrisis in z’n werk ging. Tijdens de pandemie had het collectief de voorstelling TM, een een-op-een theaterstuk via je webcam.
“Magic forest” in the Meow Wolf’s House of Eternal Return in Santa Fe. 📷 HK
Meow Wolf
Mijn eerste echte “immersieve ervaring” buiten het theater was House of Eternal Return van het Amerikaanse Meow Wolf. In 2016 openden ze een gigantische kunstinstallatie in een oude bowlingbaan in Santa Fe, mede betaald door Game of Thrones-auteur (en Santa Fean) George R. R. Martin. Er waren geen acteurs, maar wel tientallen ruimtes vol met bizarre kunstinstallaties en objecten die een verhaal vertellen. Het ene moment speel je met een stok muziek op de botten van een mammoet-skelet. Het andere moment ontdek je een wasmachine met een glijbaan naar een andere wereld. Een soort van combinatie tussen het sprookjesbos in de Efteling, een escaperoom en een hele serie kunstinstallaties en dan terwijl je paddo’s of LSD op hebt.
Meow Wolf is enorm gegroeid sinds 2016. Ze hebben een paar honderd medewerkers en sinds eind vorig jaar twee nieuwe locaties in Las Vegas en Denver.
Een andere pionier in het veld is het Britse theatergezelschap Punchdrunk. Hun op Macbeth-geïnspireerde stuk Sleep No More (oorspronkelijk uit 2003) speelt sinds 2011 in een voormalig pakhuis van vijf verdiepingen in New York. Bij binnenkomst krijg je een masker op en een speelkaart. Daarna word je in een lift gezet en ga je er op een verdieping uit, waarna je vrij rond kunt lopen. Het stuk is vrijwel tekstloos, maar wel voorzien van muziek, dans en performance. Tijdens je ervaring kun je een “een-op-een” ervaring krijgen met een van de acteurs. De ervaring kan intens zijn, met naaktscènes, lichteffecten en macabere performances.
De entree van Hotel Wonderland. Je kan binnen geen foto’s maken. 📷 HK
Hotel Wonderland
Sinds dit jaar is er eindelijk een vergelijkbare ervaring in Nederland. In een voormalige wapenfabriek van 4.000 vierkante meter op het Hembrugterrein in Zaandam is sinds half april Hotel Wonderland gevestigd. Op kosten van Hotel Wonderland mocht ik een kijkje nemen. Ik bezocht de ervaring samen met immersive storytelling-expert Nienke Huitenga (die eerder Sleep No More had gedaan).
Het concept van Hotel Wonderland zit een beetje in tussen dat van Meow Wolf en Sleep No More. De voormalige fabriek is omgebouwd tot een set met meerdere installaties. Daar zit bijvoorbeeld een autodealer tussen bedolven onder zand. Een hut van takken waar je naar een rustgevende video over wolken kan kijken. En een enorme boomhut met uitzicht over de hal. Overal hoor je een sfeervolle muziektrack.
In de installatie lopen 12 acteurs rond die je kan volgen en met wie je kunt interacteren tijdens de voorstelling die zo’n drie uur duurt. Soms komen de karakters samen in duoscènes. Twee keer is er een gezamenlijke performance, inclusief de afsluiting. De sfeervolle muziek, installaties en sets sluiten hier goed op aan voor extra effect.
But is it immersive?
Nienke en ik hebben een toffe avond gehad. En konden Hotel Wonderland goed vergelijken met Meow Wolf, Sleep No More en andere immersieve ervaringen.
Dan de hamvraag: is Hotel Wonderland immersief genoeg? We kwamen tot de conclusie dat dit helaas (nog) niet het geval is.
Een vreemde keuze is bijvoorbeeld dat er eten wordt geserveerd. Overal loopt horecapersoneel rond met hapjes, en op vier plekken in de ruimte is een horecapunt ingericht voor drankjes. Het is lastig om ‘in de ervaring’ te blijven als er de hele tijd horecapersoneel rondloopt en je overal het licht ziet van de koelingen voor de drankjes en keukens.
De sets zijn fraai gemaakt, maar ze passen niet in die enorme hal, waardoor je meer het gevoel “industriehal met standjes” krijgt dan “immersieve ervaring”. De sets lijken voornamelijk ingericht met ingekochte spullen van (kringloop)winkels waardoor een consistente stijl ontbreekt. Dit in tegenstelling tot bijvoorbeeld Meow Wolf waar alles speciaal is ontworpen en gebouwd voor de ervaring.
Naar de aanloop van de avond krijg je een boel mailtjes waarin het hele verhaal alvast uit de doeken wordt gedaan, inclusief een ‘handleiding’ voor hoe je moet omgaan met deze immersieve ervaring. Dat haalt een hoop van de spanning en het verrassingseffect weg. Bij Sleep No More weet je bijvoorbeeld helemaal niks van tevoren en word je zonder enige voorbereiding in het diepe gegooid.
Dan de prijs. Voor een avond Hotel Wonderland betaal je (inclusief eten, exclusief drank) €95 per persoon. Een flink bedrag, maar op zich niet buitensporig gezien al het personeel dat er op een avond rondloopt en de kosten om zo’n plek neer te zetten (Sleep No More heeft een vergelijkbare entreeprijs). Maar voor dat bedrag verwacht ik dan wel een avond van hoge kwaliteit waar je totaal in wordt ondergedompeld. En dat is Hotel Wonderland op dit moment niet.
Maar dat betekent niet dat het dat wel zou kunnen worden. De potentie is er zeker. En €95 is natuurlijk nog steeds goedkoper dan een vlucht naar Santa Fe of New York voor de betere ervaringen.
Hopelijk kan er genoeg aan het concept worden gesleuteld om het wel écht immersief te maken. En volgen er nog vele andere initiatieven op dit gebied, zodat we niet naar het buitenland hoeven om zo’n magische ervaring te ondergaan.
Iedereen heeft wel eens een idee voor een goed project. Maar hoe kom je van een idee tot iets echts? Dat doe je met deze zeven simpele vragen.
Download the form in English at the bottom of this page.
Zo begon het
Ik bouw websites en andere digitale producten. Vaak zijn dat opdrachten van klanten. Maar vaak zijn het ook eigen ideeën. Die ideeën beginnen als een simpel regeltje in mijn to-do app. Daar heb ik een lijstje met de naam “idee”. Daar staan dan dingen in als “goodreads voor podcasts”, “kookboek voor studenten” en “raad de tweet”.
De teller in mijn ideeënlijstje staat op 428. Ik betwijfel of ik ze ooit alle 428 ga maken. Maar ik was wel ooit enthousiast over al deze ideeën. De vraag is dus niet hoe je een idee bedenkt, maar hoe je het afmaakt. Uitstelgedrag ligt altijd op de loer, en zo blijven die 428 ideeën alleen maar regeltjes in een todo-lijstje. Hoe kom je naar iets echts?
Mijn ervaring is dat de oplossing is: het idee zo snel mogelijk echt maken. Dat kan in de vorm van een prototype. Of een schets. Of desnoods een afspraak met iemand, en dus gelijk een deadline. Maar ook daar zit eigenlijk nog een stap voor: namelijk duidelijker krijgen wat je wilt gaan doen met het idee. “Scherp maken” noemden mijn leraren op de kunstacademie dat. En daarvoor heb ik iets bedacht: het projectidee-formulier.
Het projectidee-formulier
Het projectidee-formulier (ik sta open voor een betere naam) is een simpel formulier met zeven vragen. Je vult het in als je jouw idee wilt gaan uitwerken. Je kunt het digitaal invullen, maar ik raad aan om het de eerste paar keer uit te printen en met de hand in te vullen. Dan neem je er automatisch meer tijd voor.
Je hoeft er niet al te lang over te doen. Een kwartier is genoeg. Ook als je niet tevreden bent over wat je invult is dat prima. Het hoeft niet gelijk perfect te zijn. Het gaat alleen om een eerste stap te zetten in het duidelijk maken van je idee.
Vragen
Hier zijn de zeven vragen:
1. Geef je project een naam. Een naam ergens aan geven maakt het echter. Ook hier geldt weer: maak het jezelf niet te lastig. De naam kan altijd nog veranderen en hoeft niet perfect te zijn. Zolang het maar niet “Mijn nieuwe toffe projectje” is.
2. Schrijf in één tweet (280 tekens) op wat dit project is. Je moet je idee kunnen uitleggen aan andere mensen. Als is het maar om tips te krijgen. Het in een tweet proberen uit te leggen dwingt je om na te denken hoe andere mensen je project gaan begrijpen.
3. Hoe ziet dit project eruit in de meest minimale, maar wel bruikbare vorm? Het gevaar is dat je het project té complex maakt. Dat je te veel toeters en bellen toevoegt. Daarom omschrijf je hier de meest eenvoudige uitwerking van je idee. Het zogenaamde minimum viable product.
4. Hoeveel tijd kost het om die vorm te maken? Hier maak je een ruwe, maar realistische schatting hoeveel tijd je kwijt bent aan het maken van de eenvoudigste versie van je project. Bij voorkeur doe je dit in uren. Zo kom je er vanzelf achter of het toch meer tijd kost dan je denkt.
5. Wat hoop je dat dit project oplevert? Waarom doe je dit? Soms bedenk je iets, maar kom je er later achter dat je er eigenlijk helemaal geen zin in hebt. Of dat het misschien wel een goed idee leek, maar dat eigenlijk niet is. Daarom is deze vraag belangrijk. Let op: dat het project iets “oplevert” gaat zeker niet alleen over geld! Een project kan je ook plezier opleveren, of je kan er iets van leren.
6. Waarom zou je dit niet doen? Waarom kan het mislukken? Elk project kent valkuilen. Dat hoeft je niet tegen te houden, maar het is wel goed om er rekening mee te houden. Dit kan ook een goede manier zijn om je ureninschatting (vraag 4) bij te stellen.
7. Vraag iemand om een eerste reactie te geven op dit idee. Een goed idee ontstaat niet in een vacuüm. Anderen kunnen een nieuw perspectief bieden op je idee. Daarom geef je jouw ingevulde formulier aan iemand anders voor een reactie. Het beste werkt het als die persoon eerst je formulier doorleest, dan een reactie geeft en jullie er dan over in gesprek gaan.
Dan blijkt waarschijnlijk dat je jouw idee moet bijstellen. En dat is helemaal niet erg: je kan prima meerdere versies van je idee maken en het formulier aanvullen.
Het formulier kun je via de onderstaande knop downloaden. Veel succes met je idee. Als je nog vragen hebt vind je hier mijn contactgegevens.
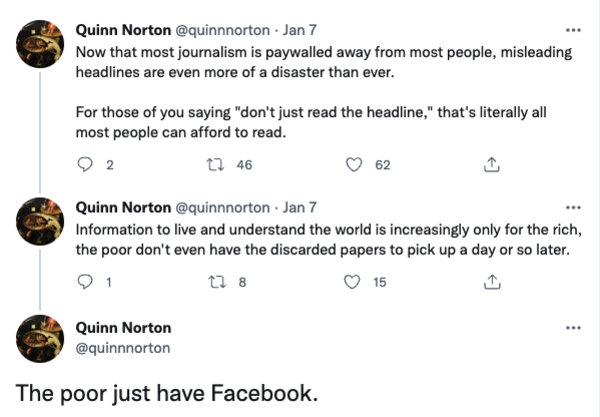
Afgelopen week zag ik deze tweets van schrijver Quinn Norton:
Haar punt: steeds meer van het web lijkt achter muren te verdwijnen. Dat kunnen betaalmuren zijn, zoals bij kranten en andere media. Of het zijn inlogmuren, zoals bij Facebook en Instagram. Het internet had de belofte dat het de wereld slimmer, eerlijker en gelijker zou maken. En ik denk dat het de wereld ook veel heeft gebracht. Maar het wordt wel steeds moeilijker om al dat moois te bekijken zonder dat je moet betalen, met geld of met je gegevens.
Dat levert een dilemma op als ik mijn nieuwsbrief De Circulaire samenstel. Elke editie kies ik vijftien linkjes uit waarvan ik denk dat het de tijd van mijn lezers waard is. Maar vaak zitten die linkjes achter een muurtje. Elk jaar hou ik een lezersenquête, en in die van afgelopen jaar schreven mensen: vermijd die linkjes gewoon. Maar is dat de oplossing?
Analyse
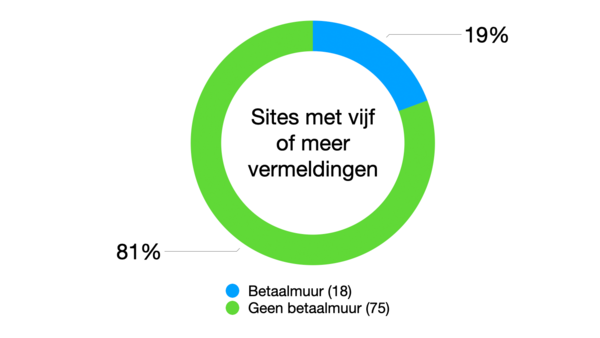
Over hoeveel linkjes hebben we het eigenlijk? Ik dook in het archief van mijn nieuwsbrief en maakte van alle edities van deze nieuwsbrief van de afgelopen vijf jaar een analyse. In 112 Circulaires stonden zo’n 3.200 unieke URL’s, van ongeveer 1.000 verschillende sites. Naar bijna 93 sites linkte ik vijf keer of vaker, gemiddeld één keer per jaar. En van die 93 hadden er 18 een soort paywall.
In die betaalmuren zit veel variatie. Bij de Washington Post kun je vrijwel niks lezen zonder te betalen. Bij Follow the Money kan het tot 24 uur na publicatie. Bij De Correspondent kun je artikelen lezen, mits ze gedeeld zijn door betalende abonnees.
Ik betaal voor een aantal sites, maar voor de meeste niet. Want als ik voor die 18 sites het goedkoopste abonnement zou afsluiten zou ik per maand €180 kwijt zijn.
Erfzonde
€180 per maand klinkt als veel geld. Maar dat komt ook door een verwachting: dat alles op het web gratis is. Dat zijn we gewend, maar het is geen natuurwet. Het internet werd opgezet vanuit overheden en de academische wereld met publiek geld, zonder business model. Met de gevolgen van die opzet worstelen we nu nog steeds.
Webontwikkelaar Peter-Paul Koch noemt dat de erfzonde van het web. Er was in het begin geen goede manier om te betalen voor content, en dat interesseerde de eerste producenten van die content ook niet zo. Die waren bezig met hun homepage op te tuigen met foto’s van hun kat en favoriete karakters uit Star Trek. Dat de traditionele media dat model overnamen en hun producten gratis weggaven zorgde ervoor dat mensen dachten dat ze er ook recht op hadden: free content entitlement.
Maar kwaliteit, in welke vorm dan ook, heeft een prijs. En iemand moet er op de een of andere manier voor betalen. Dat mensen nu verwachten dat alles online gratis is heeft Facebook en Google de middelen gegeven om mensen te laten betalen met hun privacy in plaats van met geld.
Publieke functie
Een complicerende factor is dat niet alle websites hetzelfde publiek hebben. Dat een site met juridische artikelen voor advocaten achter een betaalmuur zit lijkt me niet zo gek. Dat is specifieke informatie voor een kleine groep, die het meestal kan betalen. Massamedia hebben echter een rol in het publieke debat. Dat debat wordt gevoerd op basis van onthullende onderzoeksjournalistiek en opiniestukken. Maar als die stukken alleen beschikbaar zijn voor een kleine groep mensen die het kunnen betalen, is dat debat dan nog wel zo publiek?
De essentie wordt ook wel verspreid via ‘gratis’ media als televisiekanalen en social media. De nuance en diepgang verdwijnt dan alleen vaak. Ja, genoeg mensen lezen sowieso alleen een kop en niet de bron. Maar hoe moeilijker je het maakt om bij die bron te komen, hoe minder mensen er kennis van zullen nemen en een goed onderbouwde mening kunnen vormen.
Ik zou hier nu graag een fraaie conclusie willen geven die beter is dan: “het is ingewikkeld en ik weet het ook allemaal niet”. Wat ik hoopgevend vind is dat mensen wel degelijk bereid lijken te zijn om te betalen voor content. Met de meeste media gaat het daardoor een stuk beter dan vijftien jaar geleden werd voorspeld. Maar ik hoop ook dat media een klein achterdeurtje open blijven houden voor wie af en toe wil klikken op een linkje in mijn nieuwsbrief. Zonder dat ze moeten betalen, met hun data of met geld.
In 2003 bedacht ik dat het leuk zou zijn om een lijstje te maken met mijn favoriete muziekalbums van het jaar. Nu, achttien jaar later, doe ik dat nog steeds. In de loop der tijd zijn albums minder belangrijk geworden. Mensen luisteren inmiddels liever playlists met losse nummers. Maar albums zijn voor mij nog steeds de belangrijkste manier om naar muziek te luisteren, dus ik maak nog steeds elk jaar trouw mijn lijstje.
De albums van 2021
Bij de eerste tien albums vind je ook een eenregelige beschrijving zodat je weet waar je aan toe bent. Linkjes gaan naar het album op Spotify.
Ik heb dit jaar helaas geen enkel regulier optreden gezien. Ik zag een paar shows (hier is het hele lijstje) maar veel te weinig om een overzicht te kunnen geven.
De boeken van 2021
Begin dit jaar nam ik me voor om in 2021 elke maand een boek te lezen, twaalf in totaal dus. Ik heb nog elf dagen om het twaalfde boek uit te lezen, dus ik kan wel zeggen dat ik geslaagd ben met mijn goede voornemen.
Alle boeken die ik dit jaar las (met recensie en sterren) vind je hier. In tegenstelling tot de muziek zijn dat ook veel boeken die voor 2021 zijn gepubliceerd. Het is dus wat lastig om een lijstje te maken met de beste boeken van dit jaar.
Hoe dan ook, het beste boek dat ik las in 2021 was Because Internet van de Canadese linguist Gretchen McCulloch (uit 2019). Ze schrijft daarin hoe het internet taal en communicatie verandert. Het is zo’n zeldzaam moment dat je een boek leest en bij vrijwel elke pagina iets leest waar je door wordt verrast of denkt: “ah, dus zo zit dat”. Verplichte kost dus voor iedereen die wel eens op het internet zit.
(Toen nog) Koningin Beatrix en Willem Alexander. Het waarom van deze foto wordt duidelijk als je dit artikel helemaal hebt gelezen. 📷 Nationaal Archief / ANEFO / 934-4873 / CC-ZERO
Eerder schreef ik hier over Depictor. Dat is mijn tooltje om foto’s te taggen op Wikimedia Commons , de mediabank van de Wikimedia-projecten zoals Wikipedia. Ik schreef toen over één van de opties in dat tooltje: het toevoegen van een SPARQL-query als zoekvraag. Én ik schreef dat het te ingewikkeld was om snel uit te leggen wat SPARQL is.
Nou, dat heb ik geweten. Een paar lezers mailden me: kun je het misschien tóch uitleggen, en dan iets minder snel? Ik stuurde die mensen een uitleg terug, maar het leek me eigenlijk wel handig om dat toch ook maar hier op te schrijven. Dan kunnen mensen het ook lezen die me niet mailen. Zoals jij!
Samengevat is SPARQL een taal waar je zoekvragen mee kan schrijven om gelinkte data uit een systeem (zoals Wikidata) te halen. Eigenlijk dus een soort van Google, maar dan voor gevorderden.
Laat ik een voorbeeld geven. Koning Willem-Alexander heeft een plekje op Wikidata. Alleen dan niet met een artikel maar met een item. Alle items op Wikidata (dat zijn er op het moment van schrijven 95 miljoen) hebben een uniek nummer. Voor de koning is dat nummer Q154952 .
Prinses Beatrix, zijn moeder, heeft ook een nummer: Q29574. Beatrix en Willem-Alexander hebben een relatie: Beatrix is de moeder van Willem-Alexander. Je zegt daarom op Wikidata: item Q29574 (Beatrix) heeft als kind item Q154952 (Willem-Alexander).
Alle soorten relaties (dat zijn er meer dan 9.000) hebben óók een uniek nummer. Je kan bij zo’n relatie denken aan ‘is de hoofdstad van’, ‘is de schilder van’ of zoals bij Beatrix en Willem-Alexander: ‘heeft kind’. Het unieke nummer voor de relatie ‘heeft kind’ is op Wikidata P40. Nummers voor items (zoals de koning en zijn moeder) beginnen altijd met een ‘Q’. Nummers voor relaties (zoals ‘heeft kind’) beginnen met een ‘P’. Die ‘P’ staat trouwens voor property, want dat is hoe je een soort relatie noemt op Wikidata.
U vraagt zich wellicht af: waarom al dat gedoe met die nummers? Waarom heet Beatrix niet gewoon Beatrix? Helaas zijn namen alleen niet uniek genoeg. Er is bijvoorbeeld óók een item voor Beatrix (de voornaam, Q1096551), Beatrix (het cruiseschip, Q70114554) en Beatrix (een asteroïde, Q109927). En de persoon Beatrix zélf heeft meerdere namen. Vòòr haar abdicatie in 2013 hadden we het over ‘Koningin Beatrix’, nu over ‘Prinses Beatrix’. En in andere talen hebben ze ook weer een andere naam. In het Bulgaars hebben ze het bijvoorbeeld over ‘Беатрикс’. Namen veranderen en kunnen verschillen. Nummers veranderen nooit.
Terug naar de band tussen Beatrix en Willem-Alexander. De relatie ‘Beatrix heeft als kind Willem-Alexander’ zou je in SPARQL schrijven als:
wd:Q29574 wdt:P40 wd:Q154952
Je ziet dat er voor de items Q29574 (Beatrix) en Q154952 (Willem-Alexander) ‘wd:’ staat, en voor P40 (heeft kind) ‘wdt:’. Die letters noem je een prefix en geeft aan dat je alleen zoekt binnen Wikidata. Je kan met SPARQL namelijk ook door meerdere databases tegelijk zoeken. Dan moet wel duidelijk zijn over welke database je het hebt in je zoekvraag.
Stel dat je niet alleen Willem-Alexander zou willen vinden, maar alle kinderen van Beatrix. Dan zou je dit kunnen schrijven in SPARQL:
select ?child where { wd:Q29574 wdt:P40 ?child }
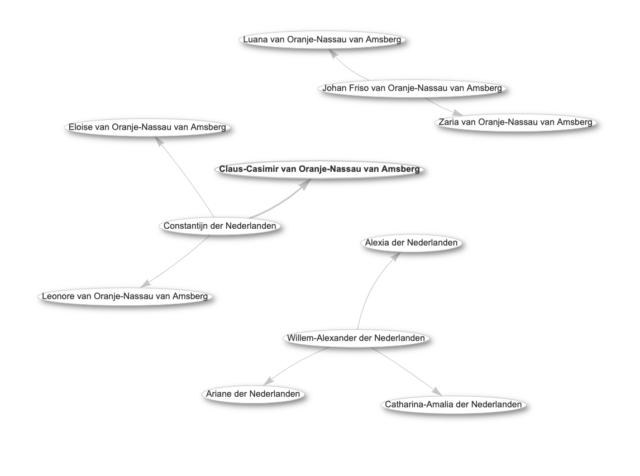
Hier staat dus zoiets als: “selecteer alle items die de relatie ‘kind van Beatrix’ hebben'”. Als je deze query (zo noem je zo’n zoekvraag) draait op de SPARQL query service van Wikidata krijg je een tabel met de nummers die horen bij Willem-Alexander, Constantijn en Friso.
Wat als je ook alle kleinkinderen van Beatrix wilt hebben? Dus de kinderen van de kinderen?
Oftewel: “selecteer alle kinderen van Beatrix, en geef me ook de kinderen van die kinderen”. Let op de punt aan het einde van elke regel om aan te geven dat je klaar bent met een triple.
Het resultaat is een lijst met 8 items: alle kleinkinderen van Beatrix mét hun vader. Voeg er nog wat extra dingen aan toe om ook de namen te krijgen (anders krijg je alleen de ID’s) en zet de netwerk-visualisatie-optie aan en je krijgt dit:
Misschien ontgaat je een beetje wat hier het praktisch nut van is. Want even googelen op ‘kleinkinderen beatrix’ levert hetzelfde op. Maar het aardige is dat je in die query alleen maar het nummer van ‘Beatrix’ hoeft te veranderen in dat van een willekeurig ander persoon met een item op Wikidata en je krijgt dáár de complete lijst van kinderen en kleinkinderen van. Of als je bijvoorbeeld álle voorouders van Willem-Alexander wilt hebben, en niet alleen z’n moeder. En het koningshuis is maar een voorbeeld. Wikidata heeft 95 miljoen items, dus of je het nou over schilderijen, monumenten of planten hebt: je kan ze gestructureerd doorzoeken.































{kind=link}